
import fastbook
fastbook.setup_book()
from fastbook import *
from fastai.vision.widgets import *
От модели к производству
Шесть строк кода, которые мы видели в < >, - это лишь небольшая часть процесса использования глубокого обучения на практике. В этой главе мы собираемся использовать пример компьютерного зрения, чтобы рассмотреть сквозной процесс создания приложения для глубокого обучения. В частности, мы собираемся создать классификатор медведей! В процессе мы обсудим возможности и ограничения глубокого обучения, узнаем, как создавать наборы данных, рассмотрим возможные проблемы при использовании глубокого обучения на практике и многое другое. Многие из ключевых моментов одинаково хорошо применимы к другим задачам глубокого обучения, например, в < >. Если вы работаете над проблемой, аналогичной по ключевым аспектам нашим примерам задач, мы ожидаем, что вы быстро получите отличные результаты с небольшим количеством кода.
Начнем с того, как вы должны сформулировать свою проблему.
Практика глубокого обучения
Мы увидели, что глубокое обучение может решить множество сложных проблем быстро и с небольшим количеством кода. Если вы новичок, у вас есть несколько проблем, которые достаточно похожи на наши примеры задач, и вы можете очень быстро получить чрезвычайно полезные результаты. Однако глубокое обучение - это не волшебство! Те же 6 строк кода не сработают для каждой проблемы, о которой сегодня можно подумать. Недооценка ограничений и переоценка возможностей глубокого обучения может привести к удручающе плохим результатам, по крайней мере, до тех пор, пока вы не наберетесь опыта и не сможете решить возникающие проблемы. И наоборот, переоценка ограничений и недооценка возможностей глубокого обучения может означать, что вы не пытаетесь решить проблему, потому что отговариваете себя от нее.
Мы часто разговариваем с людьми, которые недооценивают как ограничения, так и возможности глубокого обучения. И то, и другое может быть проблемой: недооценка возможностей означает, что вы можете даже не пробовать вещи, которые могут быть очень полезны, а недооценка ограничений может означать, что вы не учитываете важные проблемы и не реагируете на них.
Лучше всего сохранять непредвзятость. Если вы остаетесь открытыми для возможности того, что глубокое обучение может решить часть вашей проблемы с меньшим объемом данных или сложностью, чем вы ожидаете, то можно разработать процесс, в котором вы сможете найти конкретные возможности и ограничения, связанные с вашей конкретной проблемой, в процессе работы. через процесс. Это не означает, что делать какие-либо рискованные ставки - мы покажем вам, как можно постепенно развертывать модели, чтобы они не создавали значительных рисков, и даже можно протестировать их на исторических данных перед запуском в производство.
Запуск вашего проекта
Так с чего же начать свой путь глубокого обучения? Самое важное - убедиться, что у вас есть какой-то проект, над которым вы можете работать - только работая над своими собственными проектами, вы получите реальный опыт создания и использования моделей. При выборе проекта наиболее важным фактором является доступность данных. Независимо от того, выполняете ли вы проект только для собственного обучения или для практического применения в своей организации, вам нужно что-то, с чего можно было бы быстро начать работу. Мы видели, как многие студенты, исследователи и отраслевые практики тратят месяцы или годы, пытаясь найти свой идеальный набор данных. Цель состоит не в том, чтобы найти «идеальный» набор данных или проект, а в том, чтобы просто начать и продолжить оттуда.
Если вы воспользуетесь этим подходом, то вы будете на третьем этапе обучения и совершенствования, в то время как перфекционисты все еще находятся на стадии планирования!
Мы также предлагаем вам выполнить итерацию от начала до конца в своем проекте; то есть, не тратьте месяцы на точную настройку своей модели, или на полировку идеального графического интерфейса, или на маркировку идеального набора данных… Вместо этого выполняйте каждый шаг, насколько это возможно, за разумный промежуток времени до самого конца. Например, если вашей конечной целью является приложение, работающее на мобильном телефоне, то оно должно быть тем, что у вас будет после каждой итерации. Но, возможно, на ранних итерациях вы воспользуетесь некоторыми сокращениями, например, выполнив всю обработку на удаленном сервере и используя простое адаптивное веб-приложение. Завершив проект от начала до конца, вы увидите, где самые сложные моменты, и какие элементы имеют наибольшее значение для конечного результата.
По мере того, как вы работаете с этой книгой, мы предлагаем вам провести множество небольших экспериментов, запустив и настроив записные книжки, которые мы предоставляем, в то же время, когда вы постепенно разрабатываете свои собственные проекты. Таким образом, вы получите опыт работы со всеми инструментами и методами, которые мы объясняем, когда мы их обсуждаем.
s: Чтобы извлечь максимальную пользу из этой книги, найдите время поэкспериментировать между каждой главой, будь то ваш собственный проект или изучая записные книжки, которые мы предоставляем. Затем попробуйте переписать эти записные книжки с нуля на новом наборе данных. Только если вы будете много практиковаться (и терпеть неудачи), вы получите интуитивное представление о том, как обучать модель.
Используя подход сквозной итерации, вы также лучше поймете, сколько данных вам действительно нужно. Например, вы можете обнаружить, что можете легко получить только 200 помеченных элементов данных, и вы не сможете точно узнать, пока не попробуете, достаточно ли этого для получения производительности, необходимой для того, чтобы ваше приложение хорошо работало на практике.
В организационном контексте вы сможете показать своим коллегам, что ваша идея действительно работает, показав им настоящий рабочий прототип. Мы неоднократно отмечали, что это секрет получения хорошей организационной поддержки проекта.
Так как проще всего начать работу над проектом, в котором у вас уже есть данные, это означает, что, вероятно, проще всего начать работу над проектом, связанным с тем, что вы уже делаете, потому что у вас уже есть данные о том, что вы делаете. Например, если вы работаете в музыкальном бизнесе, у вас может быть доступ ко многим записям. Если вы работаете радиологом, у вас, вероятно, есть доступ к большому количеству медицинских изображений. Если вы заинтересованы в сохранении дикой природы, у вас может быть доступ к большому количеству изображений дикой природы.
Иногда нужно проявить немного творчества. Возможно, вы найдете какой-нибудь предыдущий проект машинного обучения, например конкурс Kaggle, который связан с вашей областью интересов. Иногда приходится идти на компромисс. Возможно, вы не можете найти точные данные, необходимые для конкретного проекта, который вы имеете в виду; но вы могли бы найти что-то из похожей области или измерить другим способом, решив немного другую проблему. Работа над подобными проектами по-прежнему даст вам хорошее представление об общем процессе и может помочь вам определить другие ярлыки, источники данных и т. Д.
Особенно, когда вы только начинаете с глубокого обучения, не рекомендуется расширяться в очень разные области, в те места, к которым глубокое обучение не применялось раньше. Это потому, что если ваша модель сначала не работает, вы не узнаете, была ли это ошибка, или проблема, которую вы пытаетесь решить, просто не решается с помощью глубокого обучения. И вы не будете знать, где искать помощи. Поэтому лучше всего сначала начать с чего-то, где вы можете найти пример в Интернете, где кто-то добился хороших результатов с чем-то, по крайней мере, чем-то похожим на то, что вы пытаетесь достичь, или где вы можете преобразовать свои данные в формат аналогично тому, что кто-то использовал раньше (например, создание изображения из ваших данных). Давайте посмотрим на состояние глубокого обучения,
Состояние глубокого обучения
Давайте начнем с рассмотрения того, может ли глубокое обучение помочь в решении проблемы, над которой вы хотите работать. В этом разделе представлена сводная информация о состоянии глубокого обучения на начало 2020 года. Однако все идет очень быстро, и к тому времени, когда вы прочтете это, некоторые из этих ограничений могут больше не существовать. Мы постараемся поддерживать сайт книги в актуальном состоянии; Кроме того, поиск в Google по запросу «что может делать ИИ сейчас» может дать актуальную информацию.
Компьютерное зрение
Есть много областей, в которых глубокое обучение еще не использовалось для анализа изображений, но те, где оно было опробовано, почти повсеместно показали, что компьютеры могут распознавать элементы изображения не хуже, чем люди - даже специально обученные люди. , например, радиологи. Это известно как распознавание объектов . Глубокое обучение также хорошо распознает, где находятся объекты на изображении, и может выделять их местоположение и давать имя каждому найденному объекту. Это известно как обнаружение объекта (есть также вариант этого, который мы видели в < >, где каждый пиксель классифицируется в зависимости от того, частью какого типа объекта он является - это называется сегментацией). Алгоритмы глубокого обучения, как правило, не подходят для распознавания изображений, которые существенно отличаются по структуре или стилю от изображений, используемых для обучения модели. Например, если в обучающих данных не было черно-белых изображений, модель может плохо работать с черно-белыми изображениями. Точно так же, если обучающие данные не содержат нарисованных от руки изображений, то модель, вероятно, будет плохо работать с нарисованными от руки изображениями. Не существует общего способа проверить, какие типы изображений отсутствуют в вашем обучающем наборе, но в этой главе мы покажем некоторые способы попытаться распознать, когда неожиданные типы изображений возникают в данных, когда модель используется в производственной среде (это известная как проверка данных вне домена ).
Одна из основных проблем для систем обнаружения объектов заключается в том, что нанесение меток на изображения может быть медленным и дорогостоящим. В настоящее время ведется большая работа по созданию инструментов, чтобы попытаться сделать эту маркировку быстрее и проще и потребовать меньшего количества этикеток ручной работы для обучения точным моделям обнаружения объектов. Один из подходов, который особенно полезен, - это синтетическое создание вариаций входных изображений, например, путем их поворота или изменения их яркости и контрастности; это называется увеличением данных и также хорошо работает для текстовых и других типов моделей. Мы подробно обсудим это в этой главе.
Еще один момент, который следует учитывать, заключается в том, что, хотя ваша проблема может не выглядеть как проблема компьютерного зрения, можно с небольшим воображением превратить ее в проблему. Например, если вы пытаетесь классифицировать звуки, вы можете попробовать преобразовать звуки в изображения их акустических волн, а затем обучить модель на этих изображениях.
Текст (обработка естественного языка)
Компьютеры очень хорошо классифицируют как короткие, так и длинные документы на основе таких категорий, как спам или не спам, настроения (например, положительный или отрицательный отзыв), автора, исходный веб-сайт и т. Д. Нам не известно о какой-либо серьезной работе, проделанной в этой области, чтобы сравнить их с людьми, но, по некоторым данным, нам кажется, что эффективность глубокого обучения схожа с производительностью человека при выполнении этих задач. Глубокое обучение также очень хорошо подходит для создания контекстно-зависимого текста, такого как ответы на сообщения в социальных сетях, и имитации стиля конкретного автора. Это хорошо делает этот контент привлекательным и для людей - на самом деле, даже более убедительным, чем текст, созданный людьми. Однако глубокое обучение в настоящее время не позволяет генерировать правильные отзывы! В настоящее время у нас нет надежного способа, например, объединить базу знаний медицинской информации с моделью глубокого обучения для создания правильных с медицинской точки зрения ответов на естественном языке. Это очень опасно, потому что так легко создавать контент, который непрофессионалу кажется убедительным, но на самом деле совершенно неверен.
Другая проблема заключается в том, что контекстно-зависимые, очень убедительные ответы в социальных сетях могут быть использованы в массовом масштабе - в тысячи раз больше, чем любая из ранее замеченных ферм троллей, - для распространения дезинформации, создания беспорядков и разжигания конфликтов. Как показывает опыт, модели генерации текста всегда будут технологически немного впереди моделей, распознающих автоматически созданный текст. Например, можно использовать модель, которая может распознавать искусственно созданный контент, чтобы на самом деле улучшить генератор, который создает этот контент, до тех пор, пока модель классификации не перестанет выполнять свою задачу.
Несмотря на эти проблемы, глубокое обучение имеет множество применений в НЛП: его можно использовать для перевода текста с одного языка на другой, обобщения длинных документов во что-то, что можно быстрее усвоить, поиска всех упоминаний интересующей концепции и многого другого. К сожалению, перевод или резюме могут содержать совершенно неверную информацию! Однако производительность уже достаточно высока, чтобы многие люди использовали эти системы - например, система онлайн-перевода Google (и все другие известные нам онлайн-службы) основана на глубоком обучении.
Комбинирование текста и изображений
Способность глубокого обучения объединять текст и изображения в единую модель, как правило, намного лучше, чем интуитивно ожидает большинство людей. Например, модель глубокого обучения может быть обучена на входных изображениях с выходными заголовками, написанными на английском языке, и может научиться автоматически генерировать удивительно подходящие подписи для новых изображений! Но опять же, у нас есть то же предупреждение, что мы обсуждали в предыдущем разделе: нет гарантии, что эти подписи действительно будут правильными.
Из-за этой серьезной проблемы мы обычно рекомендуем использовать глубокое обучение не как полностью автоматизированный процесс, а как часть процесса, в котором модель и пользователь-человек тесно взаимодействуют. Это потенциально может сделать людей на порядки более производительными, чем при полностью ручных методах, и на самом деле привести к более точным процессам, чем при использовании одного человека. Например, автоматическая система может использоваться для идентификации потенциальных жертв инсульта непосредственно по результатам компьютерной томографии и отправки высокоприоритетного предупреждения, чтобы эти изображения можно было быстро просмотреть. Для лечения инсультов предусмотрено всего три часа, поэтому этот быстрый цикл обратной связи может спасти жизни. В то же время, однако, все снимки можно было бы продолжать отправлять радиологам обычным способом, так что человеческий вклад не уменьшился бы.
Табличные данные
Глубокое обучение в последнее время значительно продвинулось в анализе временных рядов и табличных данных. Однако глубокое обучение обычно используется как часть множества моделей разных типов. Если у вас уже есть система, использующая случайные леса или машины для повышения градиента (популярные инструменты табличного моделирования, о которых вы скоро узнаете), то переключение на глубокое обучение или добавление его может не привести к каким-либо существенным улучшениям. Глубокое обучение действительно значительно увеличивает разнообразие столбцов, которые вы можете включать, например столбцы, содержащие естественный язык (названия книг, обзоры и т. Д.), И столбцы категорий с высокой мощностью (т.е. Что-то, что содержит большое количество дискретных вариантов, например, почтовый индекс или идентификатор продукта). С другой стороны, модели глубокого обучения обычно тренируются дольше, чем случайные леса или машины для повышения градиента.RAPIDS , обеспечивающий ускорение графического процессора для всего конвейера моделирования. Мы подробно рассмотрим плюсы и минусы всех этих методов в < >.
Системы рекомендаций
Системы рекомендаций - это действительно особый тип табличных данных. В частности, у них обычно есть категориальная переменная с высокой мощностью, представляющая пользователей, и другая, представляющая продукты (или что-то подобное). В такой компании, как Amazon, каждая покупка, которую когда-либо совершали ее клиенты, представляет собой гигантскую разреженную матрицу, в которой клиенты представлены в виде строк, а продукты - в виде столбцов. Получив данные в этом формате, специалисты по данным применяют некоторую форму совместной фильтрации для заполнения матрицы.. Например, если клиент A покупает продукты 1 и 10, а клиент B покупает продукты 1, 2, 4 и 10, механизм порекомендует, чтобы A покупал 2 и 4. Поскольку модели глубокого обучения хороши для обработки категориальных переменных с высокой мощностью , они неплохо справляются с системами рекомендаций. Они особенно полезны, как и для табличных данных, при объединении этих переменных с другими видами данных, такими как естественный язык или изображения. Они также могут хорошо сочетать все эти типы информации с дополнительными метаданными, представленными в виде таблиц, такими как информация о пользователях, предыдущие транзакции и т. Д.
Однако почти все подходы к машинному обучению имеют обратную сторону: они говорят вам только о том, какие продукты могут понравиться конкретному пользователю, а не о том, какие рекомендации были бы полезны для пользователя. Многие виды рекомендаций по продуктам, которые могут понравиться пользователю, могут оказаться совершенно бесполезными - например, если пользователь уже знаком с продуктами, или если это просто разные упаковки продуктов, которые они уже приобрели (например, коробочный набор романы, когда в них уже есть каждый из предметов в этом наборе). Джереми любит читать книги Терри Пратчетта, и какое-то время Amazon не рекомендовала ему ничего, кроме книг Терри Пратчетта (см. < >), Что на самом деле не помогло, потому что он уже знал об этих книгах!

Другие типы данных
Часто вы обнаружите, что типы данных, специфичные для предметной области, очень хорошо вписываются в существующие категории. Например, белковые цепочки очень похожи на документы на естественном языке в том смысле, что они представляют собой длинные последовательности дискретных токенов со сложными отношениями и смыслом на протяжении всей последовательности. И действительно, оказывается, что использование методов глубокого обучения НЛП является современным подходом для многих типов анализа белков. В качестве другого примера звуки могут быть представлены в виде спектрограмм, которые можно рассматривать как изображения; стандартные подходы к глубокому обучению изображений, как оказалось, действительно хорошо работают на спектрограммах.
Подходы к обучению ( Drivetrain Approach )
Есть много точных моделей, которые никому не нужны, и много неточных моделей, которые очень полезны. Чтобы ваша работа по моделированию была полезной на практике, вам необходимо подумать о том, как она будет использоваться. В 2012 году Джереми вместе с Маргит Цвемер и Майком Лукидесом представил метод под названием Drivetrain Approach для размышления над этой проблемой.
Drivetrain Approach, проиллюстрированный в < >, был подробно описан в «Проектировании великих продуктов данных» . Основная идея состоит в том, чтобы начать с рассмотрения вашей цели, затем подумать о том, какие действия вы можете предпринять для достижения этой цели и какие данные у вас есть (или вы можете получить), которые могут помочь, а затем построить модель, которую вы можете использовать для определения наилучшего действия, которые необходимо предпринять для достижения наилучших результатов с точки зрения вашей цели.
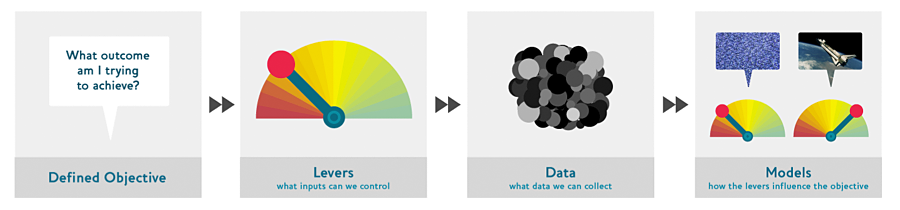
Рассмотрим модель автономного транспортного средства: вы хотите помочь автомобилю безопасно добраться из точки А в точку Б без вмешательства человека. Хорошее прогнозное моделирование - важная часть решения, но не само по себе; по мере того, как изделия становятся более изощренными, оно исчезает в сантехнике (унитазе). Кто-то, использующий беспилотный автомобиль, совершенно не подозревает о сотнях (если не тысячах) моделей и петабайтах данных, которые заставляют его работать. Но по мере того, как специалисты по обработке данных создают все более сложные продукты, им требуется систематический подход к проектированию.
Мы используем данные не только для получения дополнительных данных (в форме прогнозов), но и для получения реальных результатов . Это цель подхода Drivetrain. Начните с определения четкой цели . Например, Google, создавая свою первую поисковую систему, рассматривал «Какова основная цель пользователя при вводе поискового запроса?» Это привело их к цели - «показать наиболее релевантный результат поиска». Следующий шаг - подумать, какие рычаги вы можете использовать (т.е. какие действия вы можете предпринять), чтобы лучше достичь этой цели. В случае с Google это был рейтинг результатов поиска. Третий шаг заключался в рассмотрении того, какие новые данные им нужно будет составить такой рейтинг; они поняли, что неявная информация о том, какие страницы связаны с другими страницами, которые могут быть использованы для этой цели. Только после этих первых трех шагов мы начинаем думать о построении прогнозных моделей . Наша цель и доступные рычаги, какие данные у нас уже есть и какие дополнительные данные нам нужно будет собрать, определяют модели, которые мы можем построить. Модели будут использовать как рычаги, так и любые неконтролируемые переменные в качестве входных данных; выходные данные моделей можно комбинировать для прогнозирования конечного состояния нашей цели.
Рассмотрим другой пример: рекомендательные системы. Цель рекомендательного механизма для достижения дополнительных продаж, удивляя и радуя клиента с рекомендациями пунктов без которых бы они не приобрели ничего. Рычаг является ранжирование рекомендаций. Необходимо собрать новые данные для выработки рекомендаций, которые приведут к новым продажам . Это потребует проведения множества рандомизированных экспериментов, чтобы собрать данные о широком спектре рекомендаций для широкого круга клиентов. Это шаг, который предпринимают немногие организации; но без него у вас не будет информации, необходимой для оптимизации рекомендаций на основе вашей истинной цели (больше продаж!).
Наконец, вы можете построить две модели вероятности покупки в зависимости от того, видите ли вы рекомендацию или нет. Разница между этими двумя вероятностями является функцией полезности данной рекомендации для покупателя. Он будет низким в тех случаях, когда алгоритм рекомендует знакомую книгу, которую клиент уже отверг (оба компонента маленькие), или книгу, которую они купили бы даже без рекомендации (оба компонента большие и взаимно компенсируют друг друга).
Как видите, на практике зачастую практическая реализация ваших моделей требует гораздо большего, чем просто обучение модели! Вам часто нужно проводить эксперименты, чтобы собрать больше данных, и подумать о том, как включить ваши модели в общую систему, которую вы разрабатываете. Говоря о данных, давайте теперь сосредоточимся на том, как найти данные для вашего проекта.
Сбор данных
Для многих типов проектов вы можете найти все необходимые данные в Интернете. Проект, который мы завершим в этой главе, - это детектор медведей.. Он будет различать три типа медведей: гризли, черных и плюшевых медведей. В Интернете есть множество изображений каждого вида медведей, которые мы можем использовать. Нам просто нужен способ их найти и загрузить. Мы предоставили инструмент, который вы можете использовать для этой цели, так что вы можете следовать этой главе и создавать собственное приложение для распознавания изображений для любых типов объектов, которые вам интересны. В курсе fast.ai тысячи студентов представили свои работы на форумах курсов, показывая все, от разновидностей колибри в Тринидаде до типов автобусов в Панаме - один студент даже создал приложение, которое поможет его невесте узнать его 16 кузенов во время рождественских каникул!
На момент написания Bing Image Search - лучший из известных нам вариантов поиска и загрузки изображений. Это бесплатно для 1000 запросов в месяц, и каждый запрос может загрузить до 150 изображений. Однако между тем, когда мы написали это, и тем, когда вы читали книгу, могло произойти что-то лучшее, поэтому обязательно посетите веб-сайт книги, чтобы получить нашу текущую рекомендацию.
важно: оставаться на связи с новейшими службами: службы, которые можно использовать для создания наборов данных, постоянно появляются и исчезают, а их функции, интерфейсы и цены также регулярно меняются. В этом разделе мы покажем, как использовать API поиска изображений Bing, доступный на момент написания этой книги. Мы будем предоставлять больше возможностей и более свежую информацию на веб-сайте книги , поэтому обязательно загляните туда сейчас, чтобы получить самую свежую информацию о том, как загружать изображения из Интернета для создания набора данных для глубокого обучения.
key = os.environ.get('AZURE_SEARCH_KEY', 'XXX')
DuckDuckGo Или, если вам удобно работать с командной строкой, вы можете установить ее в своем терминале с помощью:
export AZURE_SEARCH_KEY=your_key_here
а затем перезапустите Jupyter Notebook и используйте указанную выше строку, не редактируя ее.
После того, как вы установили key, вы можете использовать search_images_bing. Эту функцию обеспечивает небольшой utilsкласс, поставляемый с ноутбуками онлайн. Если вы не знаете, где определена функция, вы можете просто ввести ее в свой блокнот, чтобы узнать:
python search_images_bing
<function fastbook.search_images_bing(key, term, min_sz=128, max_images=150)>
python search_images_ddg
<function fastbook.search_images_ddg(term, max_images=200)>
python results = search_images_ddg(key, 'grizzly bear')
ims = results.attrgot('content_url')
len(ims)
python urls = search_images_ddg('grizzly bear', max_images=100)
len(urls),urls[0]
(100, 'https://wildlifeimages.org/wp-content/uploads/2016/09/DSC1704.jpg')
Мы успешно загрузили URL-адреса 150 медведей гризли (или, по крайней мере, изображения, которые Bing Image Search находит по этому запросу).
NB : невозможно точно сказать, какие изображения найдет такой поиск. Результаты могут измениться со временем. Мы слышали по крайней мере об одном случае, когда член сообщества нашел в результатах поиска неприятные фотографии мертвых медведей. Вы получите изображения, найденные поисковой системой в Интернете. Если вы используете это на работе, с детьми и т. Д., Будьте осторожны, прежде чем отображать загруженные изображения.
Посмотрим на одно:
python from pathlib import Path
import os
import requests
cat = ['слон', 'тигр', 'коза']
for p in cat:
print(p)
urls = search_images_ddg(p, max_images=15)
print(len(urls))
c=0
path='images_data/'+p
try:
os.mkdir(path)
except OSError:
print ("Создать директорию %s не удалось" % path)
for i in urls:
try:
r=requests.get(urls[c])
if r.status_code == 200:
ext = os.path.splitext(urls[c])[1]
download_url(urls[c], path+'/'+str(c)+ext)
c+=1
print(urls[c])
print(i)
except :
passurls = search_images_ddg('grizzly bear', max_images=100)
len(urls),urls[0]download_url(urls[1], 'images_data/bear2.jpg')
im = Image.open('images_data/bear2.jpg')
im.thumbnail((256,256))
im
import sys
sys.path.append('/ai_utilities')
from ai_utilities import *
from pathlib import Path
from fastai.vision.all import *
for p in ['кот', 'заяц', 'корова']:
image_download(p, 150)
path = Path.cwd()/'dataset'
data = ImageDataLoaders.from_folder(path,valid_pct=0.2, item_tfms=Resize(224))
Кажется, это хорошо сработало, поэтому давайте воспользуемся fastai download_images для загрузки всех URL-адресов для каждого из наших поисковых запросов. Поместим каждую в отдельную папку:
bears = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(128))dls = bears.dataloaders(path)dls.valid.show_batch(max_n=6, nrows=1)
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Squish))
dls = bears.dataloaders(path)
dls.valid.show_batch(max_n=6, nrows=1)
bears = bears.new(item_tfms=Resize(128), batch_tfms=aug_transforms(mult=2))
dls = bears.dataloaders(path)
dls.train.show_batch(max_n=12, nrows=3, unique=True)
bears = bears.new(
item_tfms=RandomResizedCrop(224, min_scale=0.5),
batch_tfms=aug_transforms())
dls = bears.dataloaders(path)learn = cnn_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(4)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 2.621981 | 0.820724 | 0.342593 | 00:35 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.681638 | 0.315961 | 0.111111 | 00:54 |
| 1 | 0.500124 | 0.201040 | 0.064815 | 01:04 |
| 2 | 0.369168 | 0.183794 | 0.037037 | 01:07 |
| 3 | 0.302218 | 0.171651 | 0.037037 | 01:05 |
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()
interp.plot_top_losses(6, nrows=2)В нашей папке есть файлы изображений, как и следовало ожидать:
fns = get_image_files(path)
fns(#581) [Path('dataset/кот/000015.jpg'),Path('dataset/кот/000074.jpg'),Path('dataset/кот/000107.jpg'),Path('dataset/кот/000018.jpg'),Path('dataset/кот/000114.jpg'),Path('dataset/кот/000049.jpg'),Path('dataset/кот/000089.jpg'),Path('dataset/кот/000035.jpg'),Path('dataset/кот/000023.jpg'),Path('dataset/кот/000010.jpg')...]
j: Мне просто нравится работать с блокнотами Jupyter! Так легко постепенно создавать то, что я хочу, и проверять свою работу на каждом этапе. Я делаю много ошибок, так что это мне очень помогает ...
Часто, когда мы загружаем файлы из Интернета, некоторые из них повреждены. Давайте проверим:
failed = verify_images(fns)
failed(#0) []
Чтобы удалить все неудачные изображения, вы можете использовать unlink на каждом из них. Обратите внимание, что, как и большинство функций fastai, возвращающих коллекцию, verify_images возвращает объект типа L, который включает map метод. Это вызывает переданную функцию для каждого элемента коллекции:
failed.map(Path.unlink);Боковая панель: Получение справки в Jupyter Notebooks
Блокноты Jupyter отлично подходят для экспериментов и немедленного просмотра результатов каждой функции, но есть также множество функций, которые помогут вам понять, как использовать различные функции, или даже напрямую посмотреть их исходный код. Например, если вы введете ячейку:
??verify_imagesпоявится окно с:
Signature: verify_images(fns)
Source:
def verify_images(fns):
"Find images in `fns` that can't be opened"
return L(fns[i] for i,o in
enumerate(parallel(verify_image, fns)) if not o)
File: ~/git/fastai/fastai/vision/utils.py
Type: functionЭто говорит нам, какой аргумент принимает функция ( fns), а затем показывает нам исходный код и файл, из которого он взят. Глядя на этот исходный код, мы видим, что он применяет функцию verify_imageпараллельно и сохраняет только те файлы изображений, для которых является результат этой функции False, что согласуется со строкой документа: он находит изображения, fnsкоторые нельзя открыть.
Вот некоторые другие функции, которые очень полезны в записных книжках Jupyter:
- В любой момент, если вы не помните точное написание имени функции или аргумента, вы можете нажать Tab, чтобы получить предложения для автозаполнения.
- Если функция находится внутри скобок, одновременное нажатие клавиш Shift и Tab отобразит окно с подписью функции и кратким описанием. Двойное нажатие на эти клавиши откроет документацию, а тройное нажатие откроет полное окно с той же информацией внизу экрана.
- В ячейке при вводе ?func_nameи выполнении откроется окно с подписью функции и кратким описанием.
- В ячейке при вводе ??func_nameи выполнении откроется окно с подписью функции, кратким описанием и исходным кодом.
- Если вы используете библиотеку fastai, мы добавили doc для вас функцию: выполнение doc(func_name)в ячейке откроет окно с подписью функции, кратким описанием и ссылками на исходный код на GitHub и полной документацией функции в библиотечные документы .
- Не имеет отношения к документации, но все же очень полезен: чтобы получить помощь в любой момент, если вы получите ошибку, введите %debugследующую ячейку и выполните, чтобы открыть отладчик Python , который позволит вам проверить содержимое каждой переменной.
Конечная боковая панель
В этом процессе нужно знать одну вещь: как мы обсуждали в < >, модели могут отражать только данные, используемые для их обучения. И мир полон предвзятых данных, которые в конечном итоге отражаются, например, в поиске изображений Bing (который мы использовали для создания нашего набора данных). Например, предположим, вы были заинтересованы в создании приложения, которое могло бы помочь пользователям выяснить, здорова ли у них кожа, поэтому вы обучили модель по результатам поиска (скажем) «здоровая кожа». < > показывает, какие результаты вы получите.
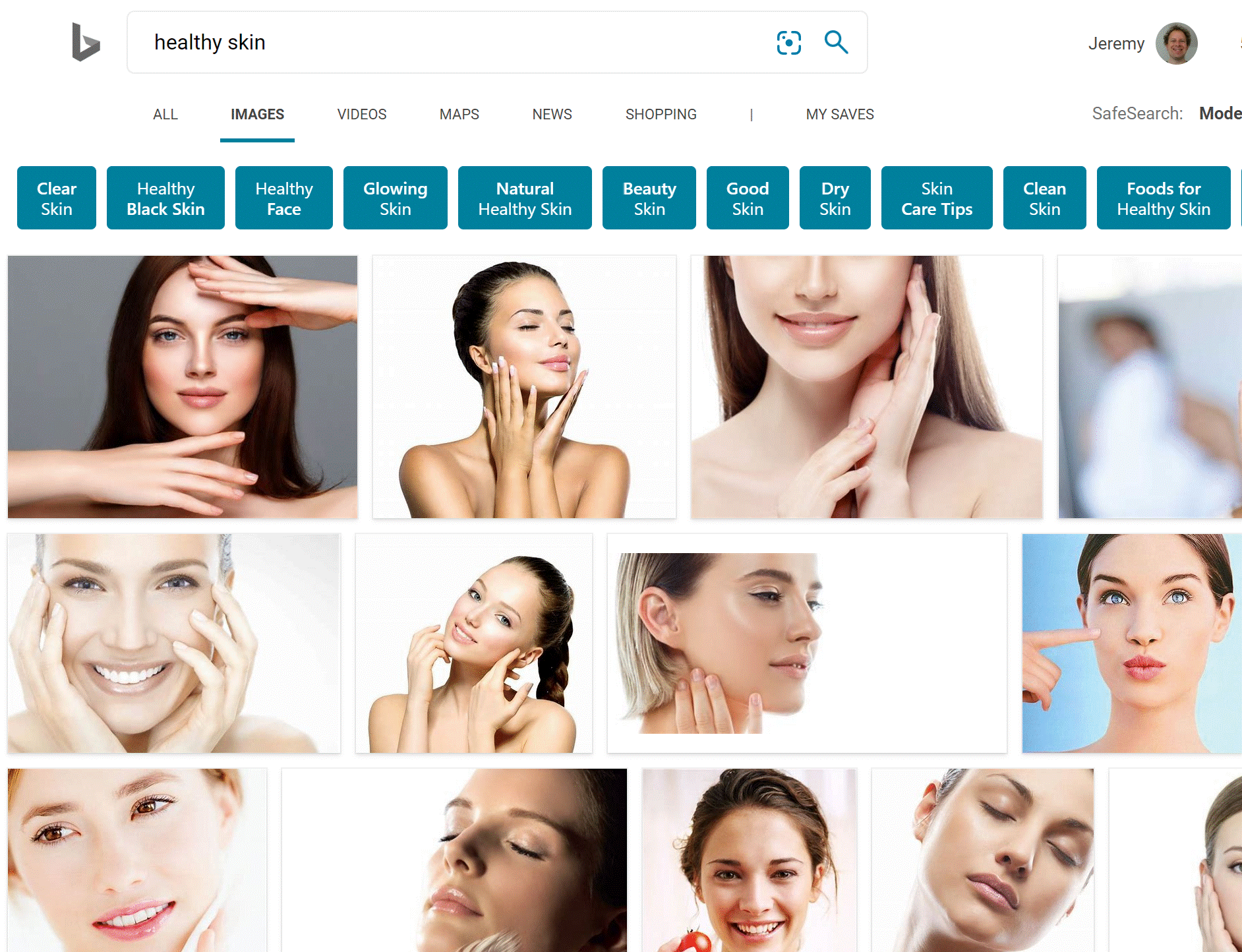
Используя это в качестве данных для тренировки, вы получите не детектор здоровой кожи, а молодую белую женщину, касающуюся детектора лица ! Обязательно подумайте о типах данных, которые вы можете ожидать увидеть на практике в своем приложении, и внимательно проверьте, чтобы все эти типы отражались в исходных данных вашей модели. сноска: Спасибо Деб Раджи, которая придумала пример «здоровой кожи».
Теперь, когда мы загрузили некоторые данные, нам нужно собрать их в формате, подходящем для обучения модели. В fastai это означает создание объекта с именем DataLoaders.
От данных к загрузчикам данных
DataLoaders- это тонкий класс, который просто хранит все объекты DataLoader, которые вы ему передаете, и делает их доступными как train и как valid. Хотя это очень простой класс, он очень важен в fastai: он предоставляет данные для вашей модели. Ключевая функциональность DataLoaders обеспечивается только этими четырьмя строками кода (у него есть некоторые другие второстепенные функции, которые мы пока пропустим):
class DataLoaders(GetAttr):
def __init__(self, *loaders): self.loaders = loaders
def __getitem__(self, i): return self.loaders[i]
train,valid = add_props(lambda i,self: self[i])жаргон: DataLoaders: класс fastai, в котором хранится несколько DataLoaderобъектов, которые вы ему передаете, обычно a train и valid, хотя возможно их сколько угодно. Первые два доступны как свойства.
Позже в этой книге вы также узнаете о Dataset и Datasets классах, которые имеют такое же отношение. Чтобы превратить загруженные данные в DataLoaders объект, нам нужно сообщить fastai как минимум четыре вещи:
- С какими данными мы работаем
- Как получить список элементов (list of items )
- Как маркировать (label) эти элементы
- Как создать набор для проверки (validation set)
До сих пор мы видели несколько фабричных методов (factory methods) для конкретных комбинаций этих вещей, которые удобны, когда у вас есть приложение и структура данных, которые подходят для этих предопределенных методов. Если вы этого не сделаете, у fastai есть чрезвычайно гибкая система, называемая API блока данных (data block API) . С помощью этого API вы можете полностью настроить каждый этап создания вашего DataLoaders. Вот что нам нужно для создания DataLoaders набора данных, который мы только что загрузили:
bears = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(128))Давайте по очереди рассмотрим каждый из этих аргументов. Сначала мы предоставляем кортеж, в котором мы указываем, какие типы мы хотим для независимых и зависимых переменных:
blocks=(ImageBlock, CategoryBlock)Независимая переменная является вещь , которую мы используем , чтобы сделать предсказания из, и зависимой переменной является нашей целью. В этом случае нашими независимыми переменными являются изображения, а нашими зависимыми переменными являются категории (тип медведя) для каждого изображения. В оставшейся части книги мы увидим много других типов блоков.
Для этого DataLoaders нашими базовыми элементами будут пути к файлам. Мы должны сообщить fastai, как получить список этих файлов. get_image_files Функция принимает путь, и возвращает список всех изображений в этом пути (рекурсивно, по умолчанию):
get_items=get_image_files Часто для загружаемых наборов данных уже определен набор проверки. Иногда это делается путем помещения изображений для обучающих и проверочных наборов в разные папки. Иногда это делается путем предоставления CSV-файла, в котором указано каждое имя файла вместе с набором данных, в котором оно должно быть. Это можно сделать разными способами, и fastai предлагает очень общий подход, который позволяет вам использовать один из предопределенных классов для этого или написать свой собственный. Однако в этом случае мы просто хотим случайным образом разделить наши наборы для обучения и проверки. Однако мы хотели бы иметь одно и то же разделение обучения / проверки каждый раз, когда мы запускаем этот блокнот, поэтому мы исправляем случайное начальное число (компьютеры вообще не знают, как создавать случайные числа, а просто создают списки чисел, которые выглядят случайными ;seed - тогда вы будете каждый раз получать один и тот же список):
splitter=RandomSplitter(valid_pct=0.2, seed=42)Независимая переменная часто упоминается как, x зависимая переменная часто упоминается как y. Здесь мы сообщаем fastai, какую функцию вызывать для создания меток в нашем наборе данных:
get_y=parent_label parent_label - это функция, предоставляемая fastai, которая просто получает имя папки, в которой находится файл. Поскольку мы помещаем каждое из наших изображений медведя в папки в зависимости от типа медведя, это даст нам нужные ярлыки.
Все наши изображения имеют разные размеры, и это проблема для глубокого обучения: мы загружаем в модель не одно изображение за раз, а несколько из них (то, что мы называем мини-пакетом (mini-batch) ). Чтобы сгруппировать их в большой массив (обычно называемый тензором ), который будет проходить через нашу модель, все они должны быть одного размера. Итак, нам нужно добавить преобразование, которое изменит размер этих изображений до того же размера. Преобразования элементов - это фрагменты кода, которые выполняются для каждого отдельного элемента, будь то изображение, категория или т.д. fastai включает множество предопределенных преобразований; Здесь мы используем преобразование Resize:
item_tfms=Resize(128) Эта команда из объекта DataBlock . Это похоже на шаблон для создания файла DataLoaders. Нам все еще нужно указать fastai фактический источник наших данных - в данном случае путь, по которому можно найти изображения:
dls = bears.dataloaders(path)A DataLoaders включает проверку и обучение DataLoader. DataLoader- это класс, который предоставляет графическому процессору партии из нескольких элементов за раз. Мы узнаем больше об этом классе в следующей главе. Когда вы проходите через DataLoader fastai, вы получаете 64 (по умолчанию) элемента за раз, и все они складываются в один тензор. Мы можем взглянуть на некоторые из этих элементов, вызвав show_batch метод для DataLoader:
dls.valid.show_batch(max_n=4, nrows=1)По умолчанию Resize обрежет изображения , чтобы соответствовать квадратной форме размера запрошенного, используя всю ширину или высоту. Это может привести к потере некоторых важных деталей. В качестве альтернативы вы можете попросить fastai заполнить изображения нулями (черными) или сжать / растянуть их:
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Squish))
dls = bears.dataloaders(path)
dls.valid.show_batch(max_n=4, nrows=1)bears = bears.new(item_tfms=Resize(128, ResizeMethod.Pad, pad_mode='zeros'))
dls = bears.dataloaders(path)
dls.valid.show_batch(max_n=4, nrows=1)Все эти подходы кажутся несколько расточительными или проблематичными. Если мы сжимаем или растягиваем изображения, они превращаются в нереалистичные формы, что обучает модель, которая узнает, что вещи выглядят иначе, чем они есть на самом деле, что, как мы ожидаем, приведет к снижению точности. Если мы кадрируем изображения, мы удаляем некоторые детали, которые позволяют нам выполнять распознавание. Например, если мы пытаемся распознать породы собак или кошек, мы можем в конечном итоге вырезать ключевую часть тела или морду, необходимую для разделения похожих пород. Если мы заполним изображения, то у нас будет много пустого пространства, что является пустой тратой вычислений для нашей модели и приводит к более низкому разрешению для той части изображения, которую мы фактически используем.
Вместо этого на практике мы обычно делаем случайный выбор части изображения и кадрируем только эту часть. В каждую эпоху (что представляет собой один полный проход через все наши изображения в наборе данных) мы случайным образом выбираем разные части каждого изображения. Это означает, что наша модель может научиться фокусироваться и распознавать различные особенности наших изображений. Это также отражает то, как изображения работают в реальном мире: разные фотографии одного и того же объекта могут быть оформлены по-разному.
Фактически, совершенно необученная нейронная сеть вообще ничего не знает о том, как ведут себя изображения. Она даже не понимает, что когда объект поворачивается на один градус, это все равно изображение того же самого объекта! Фактическое обучение нейронной сети на примерах изображений, на которых объекты находятся в немного разных местах и немного разных размеров, помогает ей понять основную концепцию того, что такое объект, и как он может быть представлен на изображении.
Вот еще один пример, в котором мы заменяем Resize на RandomResizedCrop, это преобразование, обеспечивающее только что описанное поведение. Самый важный параметр, который нужно передать, - это min_scale, который определяет, какую часть изображения выбирать каждый раз как минимум:
bears = bears.new(item_tfms=RandomResizedCrop(128, min_scale=0.3))
dls = bears.dataloaders(path)
dls.train.show_batch(max_n=4, nrows=1, unique=True)Раньше unique=True (уникальность) одно и то же изображение повторялось с разными версиями этого RandomResizedCrop преобразования. Это конкретный пример более общей техники, называемой увеличением данных (data augmentation).
Увеличение данных ( data augmentation )
Увеличение данных относится к созданию случайных вариаций наших входных данных, так что они кажутся разными, но фактически не меняют значения данных. Примерами распространенных методов увеличения данных для изображений являются вращение (rotation), отражение(flipping), искажение перспективы (perspective warping), изменение яркости (brightness) и контрастности (contrast). Для естественных фотоизображений, таких как те, которые мы используем здесь, стандартный набор дополнений, которые, как мы обнаружили, работают довольно хорошо, предоставляется с aug_transforms функцией. Поскольку наши изображения теперь имеют одинаковый размер, мы можем применить эти дополнения ко всей их партии с помощью графического процессора, что сэкономит много времени. Чтобы сообщить fastai, что мы хотим использовать эти преобразования в пакете, мы используем batch_tfms параметр (обратите внимание, что мы не используемRandomResizedCrop в этом примере, чтобы вы могли более четко видеть различия; мы также используем вдвое большее количество дополнений по сравнению со значением по умолчанию по той же причине):
bears = bears.new(item_tfms=Resize(128), batch_tfms=aug_transforms(mult=2))
dls = bears.dataloaders(path)
dls.train.show_batch(max_n=8, nrows=2, unique=True)Теперь, когда мы собрали наши данные в формате, подходящем для обучения модели, давайте фактически обучим классификатор изображений, используя его.
Обучение модели и ее использование для очистки данных
Пришло время использовать те же строки кода, что и в < >, для обучения нашего классификатора медведей.
У нас не так много данных для нашей проблемы (максимум 150 изображений каждого вида медведей), поэтому для обучения нашей модели мы будем использовать RandomResizedCrop размер изображения 224 пикселей, что является довольно стандартным для классификации изображений. и по умолчанию aug_transforms:
bears = bears.new(
item_tfms=RandomResizedCrop(224, min_scale=0.5),
batch_tfms=aug_transforms())
dls = bears.dataloaders(path)Теперь мы можем создать наш Learner и настроить его обычным способом:
learn = cnn_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(4)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 2.546822 | 0.593717 | 0.259259 | 00:41 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.630471 | 0.310475 | 0.111111 | 01:05 |
| 1 | 0.481539 | 0.174874 | 0.074074 | 01:03 |
| 2 | 0.372576 | 0.121209 | 0.046296 | 01:05 |
| 3 | 0.307564 | 0.117915 | 0.046296 | 01:09 |
Теперь давайте посмотрим, действительно ли модель ошибается, когда думает, что гризли - это плюшевые игрушки (это плохо для безопасности!), Или что гризли - черные медведи, или что-то еще. Чтобы визуализировать это, мы можем создать матрицу путаницы (confusion matrix)
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()Строки представляют всех черных, гризли и плюшевых мишек в нашем наборе данных соответственно. Столбцы представляют изображения, которые модель предсказала как черных, гризли и плюшевых мишек соответственно. Следовательно, диагональ матрицы показывает изображения, которые были классифицированы правильно, а недиагональные ячейки представляют те, которые были классифицированы неправильно. Это один из многих способов, с помощью которых fastai позволяет вам просматривать результаты вашей модели. Он (конечно!) рассчитывается с использованием набора для проверки (validation set). С помощью цветового кодирования цель состоит в том, чтобы белый цвет был везде, кроме диагонали где нужен темно-синий цвет. Наш классификатор медведей не делает много ошибок!
Полезно увидеть, где именно происходят наши ошибки, чтобы увидеть, вызваны ли они проблемой с набором данных (например, изображения, которые вообще не имеют медведей, или неправильно помечены и т.д.), Или проблемой модели (возможно, это не обрабатывает изображения, сделанные при необычном освещении, под другим углом и т. д.). Для этого мы можем отсортировать наши изображения по их потере (loss).
Потеря (loss) - это число, величина которого больше, если модель неверна (особенно если она также уверена в своем неправильном ответе) или если она верна, но не уверена в своем правильном ответе. В нескольких главах мы подробно узнаем, как рассчитываются потери и используются в тренировочном процессе. На данный момент plot_top_losses показывает нам изображения с наибольшими потерями в нашем наборе данных. Как указано в заголовке выходных данных, каждое изображение помечено четырьмя вещами: прогноз(prediction), фактическое значение (целевая метка)(target label), потеря(loss) и вероятность(probability). Вероятность (probability) здесь является уровень доверия, от нуля до единицы, правильному предсказанию модели:
interp.plot_top_losses(16, nrows=4)?interpType: ClassificationInterpretation
String form: <fastai.interpret.ClassificationInterpretation object at 0x7f4c7977c8b0>
File: /ai/2022/fastai/common/env/lib/python3.8/site-packages/fastai/interpret.py
Docstring: Interpretation methods for classification models.Эти выходные данные показывают, что изображение с наибольшими потерями - это изображение, которое было предсказано как «гризли» с высокой степенью уверенности. Однако он помечен (на основе поиска изображений Bing) как «черный». Мы не эксперты по медведям, но нам кажется, что этот ярлык неправильный! Вероятно, нам следует изменить его ярлык на «гризли».
Интуитивно понятный подход к очистке данных (data cleaning) - это сделать это до обучения модели. Но, как вы видели в этом случае, модель на самом деле может помочь вам быстрее и проще находить проблемы с данными. Итак, обычно мы предпочитаем сначала обучить быструю и простую модель, а затем использовать ее для очистки данных ( data cleaning ).
fastai включает удобный графический интерфейс для очистки данных, называемый, ImageClassifierCleaner который позволяет вам выбрать категорию и набор для обучения и проверки и просматривать изображения с наибольшими потерями (по порядку), а также меню, позволяющие выбирать изображения для удаления или изменения метки:
?ImageClassifierCleaner[0;31mInit signature:[0m [0mImageClassifierCleaner[0m[0;34m([0m[0mlearn[0m[0;34m,[0m [0mopts[0m[0;34m=[0m[0;34m([0m[0;34m)[0m[0;34m,[0m [0mheight[0m[0;34m=[0m[0;36m128[0m[0;34m,[0m [0mwidth[0m[0;34m=[0m[0;36m256[0m[0;34m,[0m [0mmax_n[0m[0;34m=[0m[0;36m30[0m[0;34m)[0m[0;34m[0m[0;34m[0m[0m [0;31mDocstring:[0m A widget that provides an `ImagesCleaner` with a CNN `Learner` [0;31mFile:[0m /ai/2022/fastai/common/env/lib/python3.8/site-packages/fastai/vision/widgets.py [0;31mType:[0m type [0;31mSubclasses:[0m
Init signature: ImageClassifierCleaner(learn, opts=(), height=128, width=256, max_n=30)
Docstring: A widget that provides an `ImagesCleaner` with a CNN `Learner`
File: /ai/2022/fastai/common/env/lib/python3.8/site-packages/fastai/vision/widgets.py
Type: type
Subclasses:
cleaner = ImageClassifierCleaner(learn, max_n=5)
cleanerVBox(children=(Dropdown(options=('dog', 'goat', 'sheep', 'заяц', 'корова', 'кот'), value='dog'), Dropdown(opti…
Мы видим, что среди наших «черных медведей» есть изображение, на котором изображены два медведя: один гризли, один черный. Итак, мы должны выбрать в меню под этим изображением. ImageClassifierCleanerна самом деле не удаляет или не меняет ярлыки за вас; он просто возвращает индексы элементов, которые нужно изменить. Так, например, чтобы удалить ( unlink) все изображения, выбранные для удаления, мы должны запустить:
for idx in cleaner.delete(): cleaner.fns[idx].unlink()Чтобы переместить изображения, для которых мы выбрали другую категорию, мы должны запустить:
for idx,cat in cleaner.change(): shutil.move(str(cleaner.fns[idx]), path/cat)s: Очистка данных и подготовка их для вашей модели - две самые большие проблемы для специалистов по данным; они говорят, что это занимает 90% их времени. Библиотека fastai предоставляет инструменты, которые максимально упрощают работу.
В этой книге мы увидим больше примеров очистки данных на основе моделей. После того, как мы очистили наши данные, мы можем повторно обучить нашу модель. Попробуйте сами и посмотрите, улучшится ли ваша точность!
Примечание. Нет необходимости в больших данных: после очистки набора данных с помощью этих шагов мы обычно наблюдаем 100% точность этой задачи. Мы даже видим этот результат, когда загружаем намного меньше изображений, чем 150 на класс, которые мы здесь используем. Как видите, распространенная жалоба на то, что вам нужны огромные объемы данных для глубокого обучения, может быть очень далекой от истины!
Теперь, когда мы обучили нашу модель, давайте посмотрим, как мы можем развернуть ее для использования на практике.
Превращение вашей модели в онлайн-приложение
Теперь мы рассмотрим, что нужно, чтобы превратить эту модель в работающее онлайн-приложение. Мы просто дойдем до создания базового рабочего прототипа; В этой книге мы не можем научить вас всем деталям разработки веб-приложений в целом.
Использование модели для вывода
Когда у вас есть модель, которой вы довольны, вам нужно сохранить ее, чтобы затем скопировать на сервер, где вы будете использовать в производстве. Помните, что модель состоит из двух частей: архитектуры и обучаемых параметров . Самый простой способ сохранить модель - сохранить их обе, потому что таким образом при загрузке модели вы можете быть уверены, что у вас есть подходящая архитектура и параметры. Чтобы сохранить обе части, воспользуйтесь exportметодом.
Этот метод даже сохраняет определение того, как создать ваш DataLoaders. Это важно, потому что в противном случае вам придется заново определять способ преобразования данных, чтобы использовать вашу модель в производстве. fastaiавтоматически использует ваш набор валидации DataLoaderдля вывода по умолчанию, поэтому ваши дополнения данных не будут применяться, что обычно именно то, что вы хотите.
Когда вы вызываете export, fastai сохранит файл под названием «export.pkl»:
learn.export()Давайте проверим, существует ли файл, используя ls метод, который fastai добавляет в Path класс Python :
path = Path()
path.ls(file_exts='.pkl')(#1) [Path('export.pkl')]
Этот файл понадобится вам везде, где вы развертываете свое приложение. А пока давайте попробуем создать простое приложение в нашем блокноте.
Когда мы используем модель для получения прогнозов, вместо обучения, мы называем это выводом (inference). Для создания нашего обучаемого логического вывода (inference) из экспортированного файла мы используем load_learner(в данном случае в этом нет особой необходимости, так как у нас уже есть рабочий файл Learner в нашей записной книжке; мы просто делаем это здесь, чтобы вы могли видеть весь процесс - до конца):
learn_inf = load_learner(path/'export.pkl')Когда мы делаем вывод (inference), мы обычно получаем прогнозы (prediction) только для одного изображения за раз. Для этого передайте имя файла в predict:
learn_inf.predict('images_data/слон/21.jpg')('корова',
TensorBase(4),
TensorBase([9.9733e-05, 4.3893e-04, 1.4814e-01, 1.8052e-04, 8.4993e-01, 1.2065e-03]))
Это вернуло три вещи: прогнозируемую категорию в том же формате, который вы изначально предоставили (в данном случае это строка), индекс прогнозируемой категории и вероятности каждой категории. Последние два основаны на порядке категорий в Vocab из DataLoaders; то есть сохраненный список всех возможных категорий. Во время вывода вы можете получить доступ к DataLoaders как атрибуту Learner:
learn_inf.dls.vocab['dog', 'goat', 'sheep', 'заяц', 'корова', 'кот']
Здесь мы можем видеть, что если мы проиндексируем словарь с возвращенным целым числом, то predict вернет «гризли», как и ожидалось. Также обратите внимание, что если мы проиндексируем список вероятностей, мы увидим почти 1,00 вероятность того, что это гризли.
Мы знаем, как делать прогнозы на основе сохраненной модели, поэтому у нас есть все необходимое для начала создания нашего приложения. Мы можем сделать это прямо в блокноте Jupyter.
Создание приложения Notebook из модели
Чтобы использовать нашу модель в приложении, мы можем просто рассматривать метод predict как обычную функцию. Следовательно, создание приложения на основе модели может быть выполнено с использованием любого из множества фреймворков и методов, доступных разработчикам приложений.
Однако большинство специалистов по данным не знакомы с миром разработки веб-приложений. Итак, давайте попробуем использовать то, что вы уже знаете: оказывается, мы можем создать полное рабочее веб-приложение, используя только записные книжки Jupyter! Для этого нам нужны две вещи:
- Виджеты IPython (ipywidgets)
- Voilà
Виджеты IPython - это компоненты графического интерфейса, которые объединяют функции JavaScript и Python в веб-браузере и могут быть созданы и использованы в ноутбуке Jupyter. Например, средство очистки изображений, которое мы видели ранее в этой главе, полностью написано с использованием виджетов IPython. Однако мы не хотим, чтобы пользователи нашего приложения запускали Jupyter самостоятельно.
Вот почему существует Voilà . Это система для предоставления конечным пользователям приложений, состоящих из виджетов IPython, без необходимости использования Jupyter. Voilà использует тот факт, что блокнот уже является своего рода веб-приложением, но довольно сложным, которое зависит от другого веб-приложения: самого Jupyter. По сути, это помогает нам автоматически преобразовывать сложное веб-приложение, которое мы уже неявно создали (ноутбук -the notebook), в более простое и легкое в развертывании веб-приложение, которое работает как обычное веб-приложение, а не как ноутбук (the notebook).
Но у нас все еще есть преимущество разработки в ноутбуке, поэтому с помощью ipywidgets мы можем создавать наш графический интерфейс шаг за шагом. Мы будем использовать этот подход для создания простого классификатора изображений. Для начала нам понадобится виджет загрузки файлов:
from ipywidgets import FileUpload
upload = FileUpload()
uploadFileUpload(value={}, description='Upload')
btn_upload = widgets.FileUpload()
btn_uploadFileUpload(value={}, description='Upload')
btn_upload = SimpleNamespace(data = ['images_data/слон/21.jpg'])Теперь мы можем взять изображение:
img = PILImage.create(btn_upload.data[-1])Мы можем использовать Output виджет для его отображения:
#hide_output
out_pl = widgets.Output()
out_pl.clear_output()
with out_pl: display(img.to_thumb(128,128))
out_plOutput()
Теперь мы можем получить наши прогнозы:
pred,pred_idx,probs = learn_inf.predict(img)и использовать Label для их отображения:
Нам понадобится кнопка, чтобы провести классификацию. Выглядит в точности как кнопка загрузки:
#hide_output
btn_run = widgets.Button(description='Classify')
btn_runButton(description='Classify', style=ButtonStyle())
Нам также понадобится обработчик события щелчка ; то есть функция, которая будет вызываться при нажатии. Мы можем просто скопировать строки кода сверху:
def on_click_classify(change):
img = PILImage.create(btn_upload.data[-1])
out_pl.clear_output()
with out_pl: display(img.to_thumb(128,128))
pred,pred_idx,probs = learn_inf.predict(img)
lbl_pred.value = f'Prediction: {pred}; Probability: {probs[pred_idx]:.04f}'
btn_run.on_click(on_click_classify)Теперь вы можете протестировать кнопку, нажав на нее, и вы увидите, что изображение и прогнозы обновляются автоматически!
#hide
#Putting back btn_upload to a widget for next cell
btn_upload = widgets.FileUpload()Теперь мы можем поместить их все в вертикальное поле ( VBox), чтобы завершить наш графический интерфейс:
#hide_output
VBox([widgets.Label('Select your bear!'),
btn_upload, btn_run, out_pl, lbl_pred])Мы написали весь код, необходимый для нашего приложения. Следующий шаг - преобразовать его во что-то, что мы можем развернуть.
Превратите свой ноутбук в настоящее приложение
#hide
# !pip install voila
# !jupyter serverextension enable --sys-prefix voila Теперь, когда у нас все работает в этом ноутбуке Jupyter, мы можем создать наше приложение. Для этого запустите новый ноутбук и добавьте в него только код, необходимый для создания и отображения нужных вам виджетов, а также разметку для любого текста, который вы хотите отобразить. Взгляните на ноутбук bear_classifier в репозитории книги, чтобы увидеть простое приложение для ноутбука, которое мы создали.
Затем установите Voilà, если вы еще этого не сделали, скопировав эти строки в ячейку ноутбука и выполнив ее:
!pip install voila
!jupyter serverextension enable --sys-prefix voilaЯчейки, начинающиеся с !, не содержат кода Python, а вместо этого содержат код, который передается в вашу оболочку (bash, Windows PowerShell и т.д.). Если вам удобно использовать командную строку, о которой мы поговорим позже в этой книге, вы, конечно, можете просто ввести эти две строки (без ! префикса) прямо в свой терминал. В этом случае первая строка устанавливает voilaбиблиотеку и приложение, а вторая подключает их к существующему ноутбуку Jupyter.
Voilà запускает ноутбуки Jupyter точно так же, как сервер ноутбука Jupyter, который вы используете сейчас, но он также делает кое-что очень важное: удаляет все входные данные ячеек и показывает только выходные данные (включая ipywidgets) вместе с вашими ячейками разметки. Итак, что получилось - это веб-приложение! Чтобы просмотреть ноутбук как веб-приложение Voilà, замените слово «ноутбук» в URL-адресе браузера на: «вуаля / рендеринг» (voila/render). Вы увидите то же содержимое, что и ваш ноутбук, но без каких-либо ячеек кода.
Конечно, вам не нужно использовать Voilà или ipywidgets. Ваша модель - это просто функция, которую вы можете вызвать ( pred,pred_idx,probs = learn.predict(img)), поэтому вы можете использовать ее с любой структурой, размещенной на любой платформе. И вы можете взять что-то, что вы прототипировали в ipywidgets и Voilà, а затем преобразовать это в обычное веб-приложение. Мы показываем вам этот подход в книге, потому что считаем, что это отличный способ для специалистов по данным и других людей, не являющихся экспертами по веб-разработке, создавать приложения на основе своих моделей.
У нас есть приложение, теперь давайте его развернем!
Развертывание вашего приложения
Как вы теперь знаете, вам понадобится графический процессор для обучения практически любой полезной модели глубокого обучения. Итак, нужен ли вам графический процессор для использования этой модели в производстве? Нет! Вам почти наверняка не понадобится графический процессор для обслуживания вашей модели в производстве . На это есть несколько причин:
- Как мы видели, графические процессоры полезны только тогда, когда они параллельно выполняют много идентичной работы. Если вы выполняете (скажем) классификацию изображений, то обычно вы будете классифицировать только одно изображение пользователя за раз, и обычно не хватает работы для одного изображения, чтобы GPU был занят достаточно долго для этого. быть очень эффективным. Таким образом, процессор часто оказывается более экономичным.
- Альтернативой может быть ожидание, пока несколько пользователей отправят свои изображения, а затем объединить их и обработать все сразу на графическом процессоре. Но тогда вы просите своих пользователей подождать, а не сразу получать ответы! И вам нужен сайт с большим объемом, чтобы это работало. Если вам действительно нужна эта функция, вы можете использовать такой инструмент, как Microsoft ONNX Runtime или AWS Sagemaker.
- Сложности работы с выводом графического процессора значительны. В частности, памятью графического процессора потребуется тщательное ручное управление, и вам понадобится тщательная система очередей, чтобы гарантировать, что вы обрабатываете только один пакет за раз.
- На рынке ЦП гораздо больше рыночной конкуренции, чем в серверах с графическим процессором, в результате чего для серверов ЦП доступны гораздо более дешевые варианты.
Из-за сложности обслуживания GPU возникло множество систем, пытающихся автоматизировать это. Однако управление этими системами и их эксплуатация также сложны и обычно требуют компиляции вашей модели в другую форму, специализированную для этой системы. Обычно предпочтительнее избегать работы с этими проблемами до тех пор, пока ваше приложение не станет достаточно популярным, чтобы это имело финансовый смысл.
По крайней мере, для начального прототипа вашего приложения и для любых хобби-проектов, которые вы хотите продемонстрировать, вы можете легко разместить их бесплатно. Лучшее место и лучший способ сделать это будут меняться со временем, поэтому проверяйте веб-сайт книги, чтобы получить самые свежие рекомендации. Поскольку мы пишем эту книгу в начале 2020 года, самый простой (и бесплатный!) подход - использовать Binder . Чтобы опубликовать свое веб-приложение в Binder, выполните следующие действия:
- Добавьте свой блокнот в репозиторий GitHub .
- Вставьте URL-адрес этого репо в URL-адрес Binder, как показано в < >.
- Измените раскрывающееся меню «Файл», чтобы выбрать URL-адрес.
- В поле «URL-адрес для открытия» "URL to open" введите /voila/render/name.ipynb(заменив name на имя своего ноутбука).
- Нажмите кнопку доски объявлений в правом нижнем углу, чтобы скопировать URL-адрес и вставить его в безопасное место.
- Щелкните "Запустить" (Launch).

В первый раз, когда вы сделаете это, Binder займет около 5 минут на создание вашего сайта. За кулисами он находит виртуальную машину, которая может запускать ваше приложение, выделять хранилище, собирает файлы, необходимые для Jupyter, для вашего ноутбука и для представления вашего ноутбука в виде веб-приложения.
Наконец, как только приложение запустится, оно появиться в вашем браузере, как новое веб-приложение. Вы можете поделиться скопированным URL-адресом, чтобы другие пользователи также могли получить доступ к вашему приложению.
Чтобы узнать о других (как бесплатных, так и платных) вариантах развертывания вашего веб-приложения, обязательно посетите веб-сайт книги.
Возможно, вы захотите развернуть свое приложение на мобильных устройствах или похожих устройствах, таких как Raspberry Pi. Существует множество библиотек и фреймворков, которые позволяют интегрировать модель непосредственно в мобильное приложение. Однако эти подходы, как правило, требуют множества дополнительных шагов и шаблонов и не всегда поддерживают все слои PyTorch и fastai, которые может использовать ваша модель. Кроме того, работа, которую вы выполняете, будет зависеть от того, на какие мобильные устройства вы нацеливаетесь для развертывания - вам может потребоваться определенная работа для запуска на устройствах iOS, другая работа для выполнения на новых устройствах Android, другая работа для старых устройств Android, и т. д. Вместо этого мы рекомендуем, где это возможно, развернуть саму модель на сервере и подключить мобильное или похожее приложение к нему как веб-службу.
У такого подхода есть немало плюсов. Первоначальная установка проще, потому что вам нужно только развернуть небольшое приложение с графическим пользовательским интерфейсом, которое подключается к серверу для выполнения всей тяжелой работы. Что еще более важно, обновления этой базовой логики могут происходить на вашем сервере, а не распространяться среди всех ваших пользователей. У вашего сервера будет намного больше памяти и вычислительной мощности, чем у большинства периферийных устройств, и гораздо проще масштабировать эти ресурсы, если ваша модель станет более требовательной. Аппаратное обеспечение, которое у вас будет на сервере, также будет более стандартным и будет более легко поддерживаться fastai и PyTorch, поэтому вам не нужно компилировать вашу модель в другую форму.
Конечно, есть и минусы. Вашему приложению потребуется сетевое соединение, и каждый раз при вызове модели будет возникать некоторая задержка. (Для запуска модели нейронной сети в любом случае требуется время, поэтому эта дополнительная сетевая задержка может не иметь большого значения для ваших пользователей на практике. Фактически, поскольку вы можете использовать лучшее оборудование на сервере, общая задержка может даже быть меньше, чем если бы оно выполнялось локально!) Кроме того, если ваше приложение использует конфиденциальные данные, ваши пользователи могут быть обеспокоены подходом, который отправляет эти данные на удаленный сервер, поэтому иногда соображения конфиденциальности будут означать, что вам нужно запустить модель на клиентском устройстве (этого можно избежать, установив локальный сервер, например, внутри брандмауэра компании). Управление сложностью и масштабирование сервера также может создавать дополнительные накладные расходы, тогда как, если ваша модель работает на клиентских устройствах, каждый пользователь привносит свои собственные вычислительные ресурсы, что приводит к более легкому масштабированию с увеличением числа пользователей (также известное как горизонтальное масштабирование) .
О: У меня была возможность воочию увидеть, как меняется ландшафт мобильного машинного обучения в моей работе. Мы предлагаем приложение для iPhone, которое зависит от компьютерного зрения, и в течение многих лет мы запускали собственные модели компьютерного зрения в облаке. Тогда это был единственный способ сделать это, поскольку эти модели требовали значительных ресурсов памяти и вычислительных ресурсов, а обработка входных данных занимала минуты. Этот подход требовал создания не только моделей (весело!), Но и инфраструктуры, чтобы гарантировать, что определенное количество «вычислительных рабочих машин» всегда будет работать (страшно), если ещё больше машин автоматически подключатся к сети, если трафик увеличится, что будет со стабильным хранилищем для больших входов и выходов, которое приложение iOS могло бы знать и сообщать пользователю, как выполнялась его работа, и т. д. В настоящее время Apple предоставляет API-интерфейсы для преобразования моделей для эффективной работы на устройстве, и большинство устройств iOS имеют выделенное оборудование машинного обучения, поэтому эту стратегию мы используем для наших новых моделей. Это все еще непросто, но в нашем случае оно того стоит, для более быстрого взаимодействия с пользователем и меньшего беспокойства о серверах. То, что работает для вас, будет реально зависеть от пользовательского опыта, который вы пытаетесь создать, и от того, что вы можете легко сделать. Если вы действительно умеете запускать сервера, сделайте это. Если вы действительно знаете, как создавать собственные мобильные приложения, сделайте это. В гору много дорог.
В целом, мы бы рекомендовали использовать простой серверный подход на базе ЦП, где это возможно, до тех пор, пока вам это сойдет с рук. Если вам посчастливится иметь очень успешное приложение, тогда вы сможете оправдать вложения в более сложные подходы к развертыванию.
Поздравляем, вы успешно создали модель глубокого обучения и развернули ее! Сейчас хорошее время, чтобы сделать паузу и подумать, что может пойти не так.
Как избежать катастрофы
На практике модель глубокого обучения будет лишь частью более крупной системы. Как мы обсуждали в начале этой главы, информационный продукт требует обдумывания всего сквозного процесса, от концепции до использования в производстве. В этой книге мы не можем надеяться охватить всю сложность управления развернутыми продуктами данных, такими как управление несколькими версиями моделей, A / B-тестирование, канарейка(canarying), обновление данных (если мы просто постоянно увеличиваем и увеличиваем наши наборы данных , или нам следует регулярно удалять некоторые из старых данных?), обрабатывать маркировку данных, отслеживать все это, обнаруживать повреждение модели и так далее. В этом разделе мы дадим обзор некоторых из наиболее важных вопросов, которые необходимо рассмотреть; для более подробного обсуждения вопросов развертывания мы отсылаем вас к превосходным приложениям на базе машинного обучения. Эммануэль Антс (О'Рейли)
Одна из самых серьезных проблем, которую следует учитывать, заключается в том, что понимание и тестирование поведения модели глубокого обучения намного сложнее, чем с большинством другого кода, который вы пишете. При обычной разработке программного обеспечения вы можете анализировать точные шаги, предпринимаемые программой, и внимательно изучать, какие из этих шагов соответствуют желаемому поведению, которое вы пытаетесь создать. Но с нейронной сетью поведение возникает из попытки модели соответствовать обучающим данным, а не быть точно определенным.
Это может привести к катастрофе! Например, предположим, что мы действительно развертывали систему обнаружения медведей, которая будет прикреплена к видеокамерам вокруг кемпингов в национальных парках и будет предупреждать отдыхающих о приближающихся медведях. Если бы мы использовали модель, обученную с использованием загруженного набора данных, на практике возникли бы всевозможные проблемы, такие как:
- Работа с видеоданными вместо изображений
- Обработка ночных изображений, которые могут не отображаться в этом наборе данных
- Работа с изображениями с камеры низкого разрешения
- Обеспечение того, чтобы результаты возвращались достаточно быстро, чтобы их можно было использовать на практике
- Распознавание медведей в позициях, которые редко можно увидеть на фотографиях, которые люди публикуют в Интернете (например, сзади, частично в кустах или далеко от камеры)
Большая часть проблемы заключается в том, что фотографии, которые люди с наибольшей вероятностью будут загружать в Интернет, - это те фотографии, которые хорошо справляются с задачей четкого и художественного отображения своей тематики - а это не те данные, которые на практике, будет получать система . Таким образом, нам может потребоваться провести большой сбор данных и их разметку, чтобы создать полезную систему.
Это лишь один из примеров более общей проблемы данных вне домена (out-of-domain data). То есть могут быть данные, которые наша модель видит в производственной среде, которые сильно отличаются от данных, которые она видела во время обучения. На самом деле нет полного технического решения этой проблемы; вместо этого мы должны быть осторожны с нашим подходом к развертыванию технологии.
Есть и другие причины, по которым нам нужно быть осторожными. Одна из очень распространенных проблем - это смещение домена (domain shift), когда тип данных, которые видит наша модель, изменяется со временем. Например, страховая компания может использовать модель глубокого обучения как часть своего алгоритма ценообразования и рисков, но со временем типы клиентов, которых привлекает компания, и типы рисков, которые они представляют, могут настолько измениться, что исходные данные обучения больше не актуально.
Данные вне домена (Out-of-domain) и смещение домена (domain shift) являются примерами более серьезной проблемы: вы никогда не сможете полностью понять все поведение своей нейронной сети. У них слишком много параметров, чтобы они могли аналитически понять все их возможное поведение. Это естественный недостаток их лучшей функции - их гибкость, которая позволяет им решать сложные проблемы, в которых мы, возможно, даже не сможем полностью указать наши предпочтительные подходы к решению. Однако хорошие новости заключаются в том, что есть способы снизить эти риски, используя тщательно продуманный процесс. Детали этого будут варьироваться в зависимости от деталей решаемой вами проблемы, но мы попытаемся изложить здесь высокоуровневый подход, кратко изложенный в < >, который, как мы надеемся, даст полезные рекомендации.
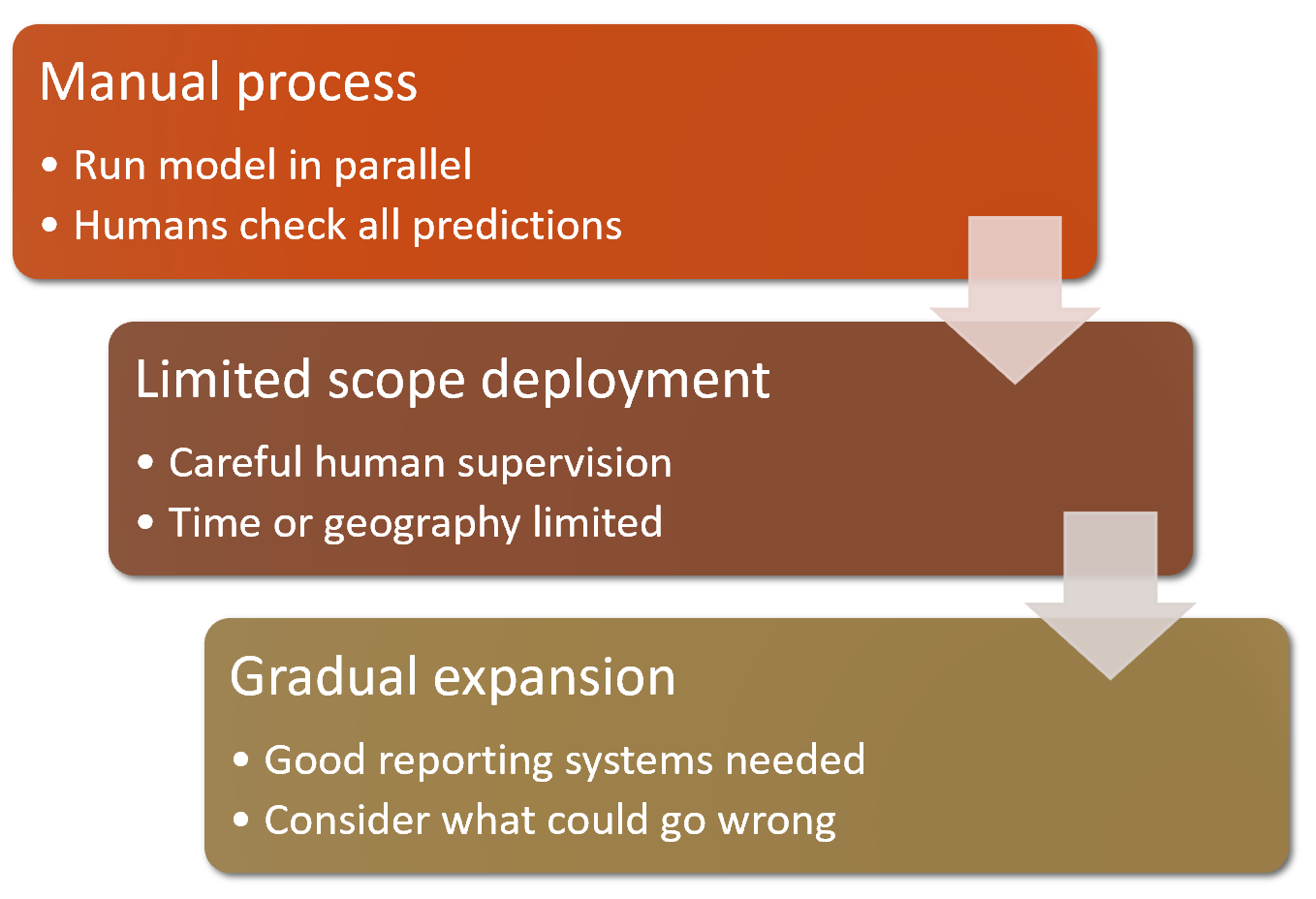
По возможности, первым шагом является использование полностью ручного процесса, при котором ваша модель глубокого обучения работает параллельно, но не используется напрямую для управления какими-либо действиями. Люди, участвующие в ручном процессе, должны смотреть на результаты глубокого обучения и проверять, имеют ли они смысл. Например, с нашим классификатором медведей у смотрителя парка может быть экран, на котором отображаются видеопотоки со всех камер, а любые возможные наблюдения медведей просто выделяются красным. Ожидается, что смотритель парка будет так же бдителен, как и до развертывания модели; модель просто помогает выявить проблемы на данном этапе.
Второй шаг - попытаться ограничить масштаб модели и обеспечить ее тщательный контроль со стороны людей. Например, проведите небольшое географическое и ограниченное по времени испытание подхода, основанного на модели. Вместо того, чтобы выкатывать наш классификатор медведей в каждом национальном парке по всей стране, мы могли бы выбрать один наблюдательный пункт на недельный период и попросить смотрителя парка проверять каждое предупреждение, прежде чем оно исчезнет.
Затем постепенно увеличивайте объем развертывания. При этом убедитесь, что у вас есть действительно хорошие системы отчетности, чтобы быть в курсе любых значительных изменений в предпринимаемых действиях по сравнению с ручным процессом. Например, если количество медвежьих предупреждений удвоится или уменьшится вдвое после развертывания новой системы в каком-либо месте, мы должны быть очень обеспокоены. Постарайтесь подумать обо всех способах, по которым ваша система может выйти из строя, а затем подумайте, какой показатель, отчет или изображение могут отражать эту проблему, и убедитесь, что ваша регулярная отчетность включает эту информацию.
Дж .: 20 лет назад я основал компанию под названием Optimal Decisions, которая использовала машинное обучение и оптимизацию, чтобы помочь гигантским страховым компаниям устанавливать цены, что снижает риски на десятки миллиардов долларов. Мы использовали подходы, описанные здесь, чтобы справиться с потенциальными недостатками в случае сбоя. Кроме того, прежде чем мы начали работать с нашими клиентами над запуском чего-либо в производство, мы попытались смоделировать воздействие, протестировав сквозную систему на их данных за предыдущий год. Запуск этих новых алгоритмов в производство всегда был довольно нервным процессом, но каждое развертывание было успешным.
Непредвиденные последствия и обратная связь
Одна из самых больших проблем при развертывании модели заключается в том, что ваша модель может изменить поведение системы, частью которой она является. Например, рассмотрим алгоритм «полицейского контроля» (predictive policing), который прогнозирует рост преступности в определенных районах, в результате чего в эти районы направляется больше полицейских, что может привести к регистрации большего количества преступлений в этих районах и т.д. В статье Королевского статистического общества(Royal Statistical Society) "Прогнозировать и служить?" Кристиан Лам и Уильям Исаак отмечают, что «предсказательная полицейская деятельность названа точно: она предсказывает будущую деятельность полиции, а не будущую преступность».
Частично проблема в этом случае состоит в том, что при наличии предвзятости (которую мы подробно обсудим в следующей главе) петли обратной связи могут привести к ухудшению негативных последствий этой предвзятости. Например, есть опасения, что это уже происходит в США, где существует значительная предвзятость в количестве арестованных по расовым мотивам. Согласно ACLU , «несмотря на примерно равные показатели употребления, вероятность ареста чернокожих за марихуану в 3,73 раза выше, чем у белых». Влияние этой предвзятости, наряду с развертыванием алгоритмов полицейского контроля, во многих частях США, побудило Бери Уильямс написать в New York Times:: «Та же технология, которая так воодушевляла меня в моей карьере, используется в правоохранительных органах таким образом, что может означать, что в ближайшие годы мой сын, которому сейчас 7 лет, с большей вероятностью будет подвергнут профилированию или аресту - или хуже - только по причине его расы и места, где мы живем ».
Полезное упражнение перед развертыванием важной системы машинного обучения - подумать над вопросом: «Что бы произошло, если бы все прошло действительно хорошо?» Другими словами, что, если предсказательная сила была чрезвычайно высокой, а ее способность влиять на поведение была чрезвычайно значительной? В таком случае, кто пострадает больше всего? Как потенциально могут выглядеть самые экстремальные результаты? Как узнать, что на самом деле происходит?
Такое мысленное упражнение может помочь вам составить более тщательный план развертывания с постоянными системами мониторинга и контролем со стороны человека. Конечно, человеческий надзор бесполезен, если к нему не прислушиваются, поэтому убедитесь, что существуют надежные и устойчивые каналы связи, чтобы нужные люди знали о проблемах и могли их исправить.
Начни писать!
Одна из вещей, которые наши студенты сочли наиболее полезными для закрепления понимания этого материала, - это его записать. Нет лучшего теста на ваше понимание темы, чем попытка научить этому кого-то другого. Это полезно, даже если вы никогда никому не показываете свое письмо - но еще лучше, если вы поделитесь им! Поэтому мы рекомендуем вам завести блог, если вы еще этого не сделали. Теперь, когда вы завершили главу 2 и узнали, как обучать и развертывать модели, у вас есть хорошие возможности для написания своего первого сообщения в блоге о своем пути к глубокому обучению. Что вас удивило? Какие возможности вы видите для глубокого обучения в своей области? Какие препятствия вы видите?
Рэйчел Томас, соучредитель fast.ai, написала в статье «Почему вы (да, вы) должны вести блог»: :
```asciidoc Главный совет, который я бы дал себе в молодости, - это начать вести блог раньше. Вот несколько причин для ведения блога:
- Это как резюме, только лучше. Я знаю нескольких человек, у которых сообщения в блогах приводили к предложениям о работе!
- Помогает учиться. Организация знаний всегда помогает мне синтезировать собственные идеи. Одна из проверок того, понимаете ли вы что-то, - можете ли вы объяснить это кому-то другому. Сообщение в блоге - отличный способ сделать это.
- Я получал приглашения на конференции и приглашения выступить из моих сообщений в блоге. Меня пригласили на саммит разработчиков TensorFlow (это было круто!) За то, что я написал в блоге сообщение о том, что мне не нравится TensorFlow.
- Встречать новых людей. Я встречал несколько человек, которые отвечали на мои сообщения в блогах.
- Экономит время. Каждый раз, когда вы несколько раз отвечаете на вопрос по электронной почте, вы должны превратить его в сообщение в блоге, чтобы вам было легче поделиться им в следующий раз, когда кто-то спросит. ``` Пожалуй, самый важный ее совет:
Вы лучше всех можете помочь людям на шаг позади вас. Материал еще свеж в вашей памяти. Многие эксперты забыли, что значит быть новичком (или продвинутым), и забыли, почему эту тему трудно понять, когда вы впервые ее слышите. Контекст вашего конкретного фона, вашего особого стиля и вашего уровня знаний придаст другой поворот тому, о чем вы пишете.
Мы предоставили полную информацию о том, как создать блог в < >. Если у вас еще нет блога, взгляните на него сейчас, потому что у нас есть действительно отличный подход, позволяющий вам начать вести блог бесплатно, без рекламы - и вы даже можете использовать Jupyter Notebook!
Опросник
- Приведите пример того, как модель классификации медведей может плохо работать в производственной среде из-за структурных или стилевых различий в данных обучения.
- Где у текстовых моделей в настоящее время есть главный недостаток?
- Каковы возможные негативные социальные последствия моделей генерации текста?
- В ситуациях, когда модель может допускать ошибки, и эти ошибки могут быть вредными, что является хорошей альтернативой автоматизации процесса?
- Какие табличные данные лучше всего подходят для глубокого обучения?
- В чем главный недостаток прямого использования модели глубокого обучения для рекомендательных систем?
- Каковы этапы Drivetrain Approach?
- Как шаги Drivetrain Approach соотносятся с системой рекомендаций?
- Создайте модель распознавания изображений, используя данные, которые вы курируете, и разверните ее в Интернете.
- Что есть DataLoaders?
- Какие четыре вещи нам нужно сказать Fastai для создания DataLoaders?
- Что делает splitter параметр DataBlock?
- Как мы можем гарантировать, что случайное разбиение всегда дает один и тот же набор проверки?
- Какие буквы часто используются для обозначения независимых и зависимых переменных?
- В чем разница между подходами к кадрированию, падению и сжатию размера? Когда вы можете выбрать одно из них?
- Что такое увеличение данных? Зачем это нужно?
- В чем разница между item_tfmsи batch_tfms?
- Что такое матрица путаницы (confusion)?
- Что делает export ?
- Как это называется, когда мы используем модель для получения прогнозов вместо обучения?
- Что такое виджеты IPython?
- Когда вы можете использовать ЦП для развертывания? Когда графический процессор может быть лучше?
- Каковы недостатки развертывания вашего приложения на сервере, а не на клиентском устройстве, таком как телефон или ПК?
- Каковы три примера проблем, которые могут возникнуть при внедрении системы предупреждения о медведях на практике?
- Что такое «данные вне домена» (Out-of-domain) ?
- Что такое «сдвиг домена» (domain shift)?
- Каковы три этапа процесса развертывания?
Дальнейшие исследования
- Подумайте, как подход Drivetrain соответствует интересующему вас проекту или проблеме.
- Когда лучше всего избегать определенных типов увеличения данных?
- Для проекта, в котором вы заинтересованы в применении глубокого обучения, рассмотрите мысленный эксперимент: «Что бы произошло, если бы все прошло действительно хорошо?»
- Начните блог и напишите свой первый пост в блоге. Например, напишите о том, для чего, по вашему мнению, глубокое обучение может быть полезно в интересующей вас области.
Метки


Раскрыть комментарии 0
Чтобы оставить комментарий , Вам необходимо Авторизоваться или пройти Регистрацию