
#hide
!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()#hide
from fastbook import *Классификация изображений
Теперь, когда вы понимаете, что такое глубокое обучение, для чего оно предназначено, как создать и развернуть модель, нам пора углубиться! В идеальном мире практики глубокого обучения не должны знать все детали того, как все работает под капотом... Но пока мы не живем в идеальном мире. Правда в том, что для того, чтобы ваша модель действительно работала и работала надежно, есть много деталей, которые вы должны получить правильно, и много деталей, которые вы должны проверить. Этот процесс требует способности заглядывать внутрь вашей нейронной сети, когда она обучается и делает прогнозы, находить возможные проблемы и знать, как их исправить.
Итак, с этого момента в книге мы собираемся глубоко погрузиться в механику глубокого обучения. Какова архитектура модели компьютерного зрения, модели НЛП, табличной модели и так далее? Как создать архитектуру, соответствующую потребностям вашей конкретной области? Как добиться наилучших результатов от тренировочного процесса? Как ускорить работу? Что вам нужно изменить при изменении ваших наборов данных? Мы начнем с повторения тех же базовых приложений, которые мы рассмотрели в первой главе, но мы сделаем две вещи:
- Сделаем их лучше.
- Используем большее количество типов данных.
Чтобы сделать эти две вещи, нам придется выучить все части головоломки глубокого обучения. Сюда входят различные типы слоев, методы регуляризации, оптимизаторы, способы объединения слоев в архитектуры, методы маркировки и многое другое. Мы не собираемся просто свалить все эти вещи на вас, хотя; мы будем внедрять их постепенно, по мере необходимости, для решения актуальных проблем, связанных с проектами, над которыми мы работаем.
От собак и кошек до пород домашних животных
В нашей самой первой модели мы узнали, как отличить собак от кошек. Всего несколько лет назад это считалось очень сложной задачей, но сегодня это слишком просто! Мы не сможем показать вам нюансы обучения моделей с этой задачей, потому что получаем почти идеальный результат, не беспокоясь ни о каких деталях. Но оказывается, что тот же набор данных также позволяет нам работать над гораздо более сложной задачей: выяснить, какая порода домашнего животного изображена на каждом изображении.
В < > мы представили приложения как уже решенные задачи. Но в реальной жизни все обстоит иначе. Мы начинаем с некоторого набора данных, о котором ничего не знаем. Затем нам нужно выяснить, как он собран, как извлечь из него нужные нам данные и как эти данные выглядят. В оставшейся части этой книги мы покажем вам, как решить эти проблемы на практике, включая все промежуточные шаги, необходимые для понимания данных, с которыми вы работаете, и тестирования вашего моделирования в процессе работы.
Мы уже загрузили набор данных Pet, и мы можем получить путь к этому набору данных, используя тот же код, что и в < >:
from fastai.vision.all import *
path = untar_data(URLs.PETS)Теперь, если мы собираемся понять, как извлечь породу каждого питомца из каждого изображения, нам нужно понять, как эти данные выкладываются. Такие детали компоновки данных являются важной частью головоломки глубокого обучения. Данные обычно предоставляются одним из следующих двух способов:
- Отдельные файлы, представляющие элементы данных, такие как текстовые документы или изображения, возможно, организованные в папки или с именами файлов, представляющими информацию об этих элементах
- Таблица данных, например в формате CSV, где каждая строка представляет собой элемент, который может включать имена файлов, обеспечивающие связь между данными в таблице и данными в других форматах, таких как текстовые документы и изображения.
Есть исключения из этих правил - особенно в таких областях, как геномика, где могут быть двоичные форматы баз данных или даже сетевые потоки,—но в целом подавляющее большинство наборов данных, с которыми вы будете работать, будут использовать некоторую комбинацию этих двух форматов.
Чтобы увидеть, что находится в нашем наборе данных, мы можем использовать метод ls:
#hide
Path.BASE_PATH = pathpath.ls()(#2) [Path('images'),Path('annotations')]
Мы видим, что этот набор данных предоставляет нам каталоги изображений и аннотаций . Веб- сайт для набора данных говорит нам, что каталог аннотаций содержит информацию о том, где находятся домашние животные, а не о том, что они собой представляют. В этой главе мы будем проводить классификацию, а не локализацию, то есть нам важно, что это за домашние животные, а не где они находятся. Поэтому пока мы проигнорируем каталог аннотаций . Итак, заглянем в каталог изображений :
(path/"images").ls()(#7393) [Path('images/British_Shorthair_199.jpg'),Path('images/Sphynx_21.jpg'),Path('images/samoyed_13.jpg'),Path('images/Maine_Coon_137.jpg'),Path('images/chihuahua_81.jpg'),Path('images/scottish_terrier_107.jpg'),Path('images/Russian_Blue_193.jpg'),Path('images/shiba_inu_30.jpg'),Path('images/Bombay_166.jpg'),Path('images/wheaten_terrier_150.jpg')...]
Большинство функций и методов в fastai, возвращающих коллекцию, используют класс L. L можно рассматривать как расширенную версию обычного списка Python с дополнительными удобствами. Например, когда мы показываем объект этого класса в ноутбуке, он появляется в формате, показанном там. Первое, что отображается, - это количество элементов в коллекции с префиксом #. В предыдущем выводе вы также увидите, что список снабжен многоточием. Это означает, что отображаются только первые несколько элементов -и это хорошо, потому что мы не хотим, чтобы на нашем экране было больше 7000 имен файлов!
Исследуя эти имена файлов, мы можем увидеть, как они выглядят структурированными. Каждое имя файла содержит породу домашних животных, а затем символ подчеркивания (_), число и, наконец, расширение файла. Нам нужно создать фрагмент кода, который извлекает породу из из одного элемента Path. Блокноты Jupyter упрощают это, потому что мы можем постепенно создавать что-то, что работает, а затем использовать это для всего набора данных.Мы должны быть осторожны, чтобы не делать слишком много предположений на этом этапе. Например, если вы внимательно посмотрите, вы можете заметить, что некоторые породы домашних животных содержат несколько слов, поэтому мы не можем просто разорвать текст на первом _ найденном символе. Чтобы мы могли протестировать наш код, давайте выберем один файл:
fname = (path/"images").ls()[0]Самый мощный и гибкий способ извлечения информации из таких последовательностей - использовать регулярное выражение, также известное как regex. Регулярное выражение - это специальная последовательность, записанная на языке регулярных выражений, которая определяет общее правило для принятия решения, проходит ли последовательность тест (т.е. «соответствует» регулярному выражению), а также, возможно, для извлечения определенной части или частей.
В этом случае нам нужно регулярное выражение, которое извлекает породу домашних животных из имени файла.
Полный учебник по регулярным выражениям,выходит за рамки данной книги, но в Интернете есть много отличных учебников, и многие из вас уже знакомы с этим замечательным инструментом. Если нет, ничего страшного - это отличная возможность исправить это! Регулярные выражения являются одним из наиболее полезных инструментов в нашем инструментарии программирования. Итак, отправляйтесь в Google и ищите «учебное пособие по регулярным выражениям» , а затем возвращайтесь сюда после изучения. На сайте книги есть небольшой список.
a: Регулярные выражения не только очень удобны, но и имеют интересные корни. Они являются «регулярными», потому что изначально были примерами «регулярного» языка, низшей ступени в иерархии Хомского, грамматической классификации, разработанной лингвистом Ноамом Хомским, который также написал Syntactic Structures, пионерскую работу по поиску формальной грамматики, лежащей в основе человеческого языка. Это одна из прелестей вычислительной техники: возможно, молоток, к которому вы тянетесь каждый день, на самом деле передан с космического корабля.
Когда вы пишете регулярное выражение, лучший способ начать - это сначала попробовать его на одном примере. Давайте воспользуемся методом findall, чтобы попробовать регулярное выражение для имени файла объекта fname:
re.findall(r'(.+)_\d+.jpg$', fname.name)['British_Shorthair']
Это регулярное выражение извлекает все символы, идущие до последнего символа подчеркивания, если символы подпоследовательности являются числовыми цифрами, а затем расширением файла JPEG.
Теперь, когда мы подтвердили, что регулярное выражение работает для этого примера, давайте воспользуемся им для маркировки всего набора данных. fastai поставляется с множеством классов, помогающих с маркировкой. Для разметки с помощью регулярных выражений мы можем использовать RegexLabeller класс. В этом примере мы используем API блока данных, который мы видели в < > (на самом деле, мы почти всегда используем API блока данных - он намного более гибкий, чем простые фабричные методы, которые мы видели в < >):
pets = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'),
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224, min_scale=0.75))
dls = pets.dataloaders(path/"images")Одна важная часть этого вызова DataBlock, которую мы не видели ранее, находится в этих двух строках:
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224, min_scale=0.75)Эти строки реализуют стратегию аугментации данных, которую мы называем предварительным вычислением presizing. Изменение размера (Presizing) - это особый способ увеличения изображения, предназначенный для минимизации разрушения данных при сохранении хорошей производительности.
Изменение размера (Presizing)
Нам нужно, чтобы наши изображения имели одинаковые размеры, чтобы они могли объединяться в тензоры для передачи в графический процессор. Мы также хотим минимизировать количество выполняемых нами отдельных вычислений. Требование к производительности предполагает, что мы должны, где это возможно, объединять наши дополнительные преобразования в меньшее количество преобразований (для уменьшения числа вычислений и количества операций с потерями) и преобразовывать изображения в одинаковые размеры (для более эффективной обработки на GPU).
Проблема заключается в том, что при выполнении преобразования, могут появиться ложные пустые зоны, ухудшиться данные или и то, и другое. Например, поворот изображения на 45 градусов заполняет угловые области новых границ пустотой, что ничему не научит модель. Многие операции поворота и масштабирования потребуют интерполяции для создания пикселей. Эти интерполированные пиксели получены из данных исходного изображения, но все же имеют более низкое качество.
Чтобы обойти эти проблемы, используются две стратегии:
- Изменение размеров изображений до относительно «больших» размеров, т.е. размеров, значительно превышающих целевые учебные размеры.
- Объединение всех операций увеличения (включая изменение размера до конечного целевого размера) в одну, в конце обработки, комбинированную операцию на графическом процессоре, вместо того, чтобы выполнять операции по отдельности и интерполировать несколько раз.
Первый шаг, изменение размера, создает достаточно большие изображения, с запасом, для преобразования во внутренних областях без создания пустых зон. Это преобразование работает путем изменения размера до квадрата с использованием большого размера кадрирования. В обучающем наборе область кадрирования выбирается случайным образом, и размер кадрирования выбирается так, чтобы покрыть всю ширину или высоту изображения, в зависимости от того, что меньше.
На втором этапе графический процессор используется для увеличения всех данных, и все потенциально деструктивные операции выполняются вместе с одной интерполяцией в конце.

На этом рисунке показаны два шага:
- Обрезка по всей ширине или высоте: Это происходит в item_tfms, поэтому она применяется к каждому отдельному изображению перед его копированием на графический процессор. Он используется для того, чтобы все изображения были одинакового размера. На обучающем наборе площадь обрезания выбирается случайным образом. В наборе проверки всегда выбирается центральный квадрат изображения.
- Случайное обрезание и увеличение: Это происходит в batch_tfms, поэтому он применяется к пакету сразу на графическом процессоре, а это значит, что он работает быстро. В проверочном наборе выполняется только изменение размера до конечного размера. На тренировочном наборе сначала выполняется случайное обрезание и любые другие преобразования.
Для реализации этого процесса в fastai вы используете Resizeкак преобразование элемента с большим размером, а RandomResizedCrop-как пакетное преобразование с меньшим размером. RandomResizedCrop может использоваться, если есть параметр min_scale в функции aug_transforms, как это было сделано в вызове DataBlock в предыдущем разделе. Кроме того, вы можете использовать pad или squish вместо crop (по умолчанию) для первоначального изменения размера.
<> показывает разницу между изображением, которое было увеличено, интерполировано, повернуто, а затем снова интерполировано (этот подход используется всеми другими библиотеками глубокого обучения), показанным здесь справа, и изображением, которое было увеличено и повернуто как одна операция, а затем интерполировано только один раз - показанным здесь слева(подход fastai).
os.listdir("images")['matmul2.svg', 'image12.png', 'att_00061.png', 'Dropout.png', 'image2.png', 'image1.png', 'att_00020.png', 'image7.png', 'image6.png', 'image8.png', 'att_00039.png', 'image17.png', 'pipeline_diagram.svg', 'grizzly.jpg', 'grad_illustration.svg', 'image11.png', 'healthy_skin.gif', 'image10.png', 'att_00062.png', 'image3.jpeg', 'att_00024.png', 'att_00058.png', 'fltscale.svg', 'att_00001.png', 'chapter2_bouncy.svg', 'att_00026.png', 'att_00025.png', 'att_00021.png', 'chapter2_small.svg', 'image4.png', 'pratchett.png', 'image13.png', 'Dropout1.png', 'att_00060.png', 'image18.jpeg', 'LSTM.png', 'att_00070.png', 'drivetrain-approach.png', 'att_00022.png', 'chapter2_div.svg', 'chapter2_perfect.svg', 'image9.jpeg']
#hide_input
#id interpolations
#caption Сравнение стратегии увеличения данных fastai (слева) и традиционного подхода (справа).
dblock1 = DataBlock(blocks=(ImageBlock(), CategoryBlock()),
get_y=parent_label,
item_tfms=Resize(460))
# Перед запуском этой папки поместите изображение во вложенную папку «images/grizzly.jpg», в которой находится этот ноутбук
dls1 = dblock1.dataloaders([(Path.cwd()/'images_data'/'тигр'/'19.jpg')]*100, bs=8)
dls1.train.get_idxs = lambda: Inf.ones
x,y = dls1.valid.one_batch()
_,axs = subplots(1, 2)
x1 = TensorImage(x.clone())
x1 = x1.affine_coord(sz=224)
x1 = x1.rotate(draw=30, p=1.)
x1 = x1.zoom(draw=1.2, p=1.)
x1 = x1.warp(draw_x=-0.2, draw_y=0.2, p=1.)
tfms = setup_aug_tfms([Rotate(draw=30, p=1, size=224), Zoom(draw=1.2, p=1., size=224),
Warp(draw_x=-0.2, draw_y=0.2, p=1., size=224)])
x = Pipeline(tfms)(x)
#x.affine_coord(coord_tfm=coord_tfm, sz=size, mode=mode, pad_mode=pad_mode)
TensorImage(x[0]).show(ctx=axs[0])
TensorImage(x1[0]).show(ctx=axs[1]);
Вы можете видеть, что изображение справа менее четко определено и имеет артефакты заполнения отражения в левом нижнем углу; кроме того, трава в левом верхнем углу полностью исчезла. Мы обнаружили, что на практике использование изменения размера значительно повышает точность моделей и часто приводит к ускорению.
Библиотека fastai также предоставляет простые способы проверки правильности внешнего вида ваших данных перед обучением модели, что является чрезвычайно важным шагом. Мы посмотрим на них в следующий раз.
Проверка и отладка блока данных (DataBlock)
Мы никогда не можем просто предположить, что наш код работает идеально. Написание DataBlock - это то же самое, что написание проекта. Вы получите сообщение об ошибке, если у вас есть синтаксическая ошибка где-то в вашем коде, но у вас нет гарантий, что ваш шаблон будет работать с вашим источником данных, как вы предполагаете. Итак, перед обучением модели вы всегда должны проверить свои данные. Это можно сделать с помощью метода show_batch:
dls.show_batch(nrows=1, ncols=3)
Взгляните на каждое изображение и убедитесь, что на каждом изображении есть правильная метка для этой породы домашних животных. Часто специалисты по обработке данных работают с данными, с которыми они не так хорошо знакомы, как эксперты по предметной области: например, я на самом деле не знаю, что такое многие из этих пород домашних животных. Поскольку я не являюсь экспертом по породам домашних животных, я бы использовал Google images, чтобы найти несколько из этих пород и убедиться, что изображения похожи на то, что я вижу.
Если вы совершили ошибку при создании DataBlock, скорее всего, вы не увидите его до этого шага. Для отладки рекомендуется использовать метод сводки - summary. Будет предпринята попытка создать пакет из указанного источника с большим количеством деталей. Кроме того, если это не удастся, вы увидите точно, в какой момент происходит ошибка, и библиотека попытается дать вам некоторую помощь. Например, одна из распространенных ошибок заключается в том, , что вы забываете использовать преобразование Resize, поэтому вы получаете изображения разных размеров и не можете их группировать. Вот как будет выглядеть резюме в этом случае (обратите внимание, что точный текст мог измениться с момента написания, но это даст вам представление):
#hide_output
pets1 = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'))
pets1.summary(path/"images")Вы можете точно увидеть, как мы собрали данные и разделили их, как мы перешли от имени файла к образцу (кортеж (изображение, категория)), затем какие преобразования элементов были применены и как нам не удалось собрать эти образцы в пакет (из-за разных форм).
Если вы считаете, что ваши данные выглядят правильно, мы обычно рекомендуем использовать их на следующем этапе для обучения простой модели. Мы часто видим, как люди слишком долго откладывают обучение реальной модели. В результате они фактически не понимают, как выглядят их базовые результаты. Возможно, ваша проблема не требует большого количества изысканной предметно-ориентированной разработки. Или, возможно, данные вообще не тренируют модель. Это то, что вы хотите узнать как можно скорее. Для этого начального теста мы будем использовать ту же простую модель, которую мы использовали в < >:
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(2)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.532537 | 0.318855 | 0.092016 | 00:34 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.514734 | 0.259010 | 0.077808 | 00:41 |
| 1 | 0.330070 | 0.214201 | 0.064953 | 00:42 |
Как мы кратко обсуждали ранее, таблица, показывает нам результаты после каждой эпохи обучения. Помните, эпоха - это один полный проход через все изображения в данных. Показанные столбцы представляют собой средние потери по элементам обучающего набора, потери в проверочном наборе и и любые определенные нами метрики - в данном случае частота ошибок.
Помните, что потеря - это функция, которую мы решили использовать для оптимизации параметров нашей модели. Но мы на самом деле не сказали fastai, какую функцию потерь мы хотим использовать. Так что же он сделает? fastai обычно пытается выбрать подходящую функцию потерь на основе того, какие данные и модель вы используете. В этом случае у нас есть данные изображения и категориальный результат, поэтому fastai будет по умолчанию использовать потери перекрестной энтропии.
Потери при перекрестной энтропии ( Cross-Entropy Loss )
Кросс-энтропийные потери-это функция потерь, которая аналогична той, которую мы использовали в предыдущей главе, но (как мы увидим) имеет два преимущества:
- Это работает даже тогда, когда наша зависимая переменная имеет более двух категорий.
- Это приводит к более быстрому и надежному обучению.
Чтобы понять, как кросс-энтропийные потери работают для зависимых переменных с более чем двумя категориями, мы сначала должны понять, как выглядят фактические данные и активации, которые видит функция потерь.
Просмотр активаций и меток
Давайте посмотрим на активацию нашей модели. Чтобы фактически получить пакет реальных данных из наших DataLoaders, можно использовать one_batch метод:
x,y = dls.one_batch()Как видно, это возвращает зависимые и независимые переменные в виде мини-пакета. Давайте посмотрим, что на самом деле содержится в нашей зависимой переменной:
yTensorCategory([ 5, 11, 20, 6, 34, 19, 21, 21, 23, 27, 3, 24, 6, 12, 23, 30, 16, 7, 34, 32, 35, 7, 9, 15, 13, 9, 28, 13, 16, 33, 18, 35, 23, 16, 18, 17, 4, 7, 35, 33, 15, 19, 29, 4, 26, 35, 7, 14,
36, 25, 4, 5, 0, 9, 35, 22, 14, 9, 35, 6, 8, 33, 31, 16], device='cuda:0')
Наш размер пакета равен 64, поэтому у нас есть 64 строки в этом тензоре. Каждая строка представляет собой одно целое число от 0 до 36, представляющее 37 возможных пород домашних животных. Мы можем просматривать предсказания (то есть активации конечного слоя нашей нейронной сети) с помощью Learner.get_press. Эта функция либо принимает индекс набора данных (0 для train и 1 для valid), либо итератор пакетов. Таким образом, мы можем передать ему простой список с нашей партией, чтобы получить наши прогнозы. Он возвращает прогнозы и цели по умолчанию, но поскольку у нас уже есть цели, мы можем эффективно игнорировать их, назначив специальной переменной _:
preds,_ = learn.get_preds(dl=[(x,y)])
preds[0]tensor([3.5280e-03, 4.9959e-01, 3.2245e-07, 1.1385e-05, 7.0161e-06, 4.9621e-01, 5.4312e-04, 7.2740e-07, 7.5992e-07, 3.0504e-06, 5.2409e-06, 4.0095e-05, 6.1325e-08, 2.1495e-07, 5.8886e-07, 5.6911e-06,
1.5484e-07, 9.7283e-06, 3.3242e-07, 5.1036e-06, 2.0480e-05, 4.9346e-08, 1.1228e-07, 3.5695e-07, 5.3538e-08, 5.4898e-07, 8.4700e-07, 7.5534e-07, 4.1037e-07, 1.5843e-06, 3.8813e-08, 1.4044e-07,
2.5593e-06, 4.6049e-06, 4.4440e-08, 3.3594e-07, 4.7489e-07])
Фактические предсказания составляют 37 вероятностей между 0 и 1, которые в сумме составляют до 1:
len(preds[0]),preds[0].sum()(37, tensor(1.))
Чтобы преобразовать активации нашей модели в предсказания, мы использовали функцию активации softmax.
Softmax
В нашей модели классификации ,в последнем слое, мы используем функцию активации softmax.Выходные значения будут находиться в интервале между 0 и 1, а сумма этих значений всегда равна 1.
Softmax похож на сигмовидную функцию, которую мы видели ранее. Напоминаем, что сигмовидная функция выглядит так:
plot_function(torch.sigmoid, min=-4,max=4)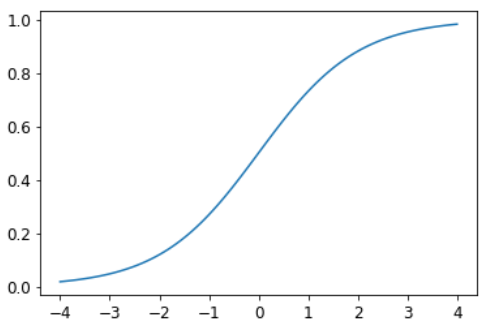
Мы можем применить эту функцию к одному слою активаций из нейронной сети и получить обратно столбец чисел от 0 до 1.
Теперь подумайте о том, что произойдет, если мы захотим иметь определять больше категорий (например, наши 37 пород домашних животных). Это означает, что нам понадобится больше активаций, чем просто один столбец: нам нужна активация для каждой категории. Например, мы можем создать, нейронную сеть, которая предсказывает 3-ки и 7-ки, которая возвращает две активации, по одной для каждого класса -это будет хорошим первым шагом к созданию более общего подхода. Давайте просто используем некоторые случайные числа со стандартным отклонением 2 (поэтому мы умножаем randn на 2) для этого примера, предполагая, что у нас есть 6 изображений и 2 возможные категории (где первый столбец представляет 3-ки, а второй- 7-ки):
torch.random.manual_seed(42);acts = torch.randn((6,2))*2
actstensor([[ 0.6734, 0.2576],
[ 0.4689, 0.4607],
[-2.2457, -0.3727],
[ 4.4164, -1.2760],
[ 0.9233, 0.5347],
[ 1.0698, 1.6187]])
Мы не можем просто взять сигмоид напрямую, так как мы не получаем строки, которые складываются в 1 (то есть мы хотим, чтобы вероятность быть 3 плюс вероятность быть 7 равнялась 1):
acts.sigmoid()tensor([[0.6623, 0.5641],
[0.6151, 0.6132],
[0.0957, 0.4079],
[0.9881, 0.2182],
[0.7157, 0.6306],
[0.7446, 0.8346]])
В < > наша нейронная сеть создавала одну активацию на изображение, которое мы пропускали через сигмовидную функцию. Эта единственная активация представляла уверенность модели в том, что входная данные — это 3. Бинарные задачи являются частным случаем задач классификации, поскольку цель может рассматриваться как одно логическое значение, как мы это сделали в mnist_loss. Но бинарные задачи также можно рассматривать в контексте более общей группы классификаторов с любым количеством категорий: в данном случае у нас есть две категории. Как мы видели в классификаторе медведя, наша нейронная сеть вернет одну активацию в каждой категории.
Итак, что же на самом деле означают эти активации в бинарном случае? Одна пара активизаций просто показывает относительную уверенность входного сигнала в 3 против того, что это 7.Общие значения, независимо от того, большие они оба или оба маленькие, не имеют значения - все, что имеет значение, это то, что больше, и на сколько.
Мы ожидаем, что, поскольку это просто другой способ представления той же проблемы, мы сможем использовать сигмоид непосредственно в двухактивационной версии нашей нейронной сети. И действительно мы можем! Мы можем просто взять разницу между активациями нейронной сети, потому что это отражает, насколько больше мы уверены, что вход подается 3-ка, чем 7-ка, а затем взять сигмоид:
(acts[:,0]-acts[:,1]).sigmoid()tensor([0.6025, 0.5021, 0.1332, 0.9966, 0.5959, 0.3661])
Второй столбец (вероятность 7-ки) будет значением которое вычитается из 1. Теперь нам нужен способ для этого, который также работает для более чем двух колонок. Оказывается, эта функция, называемая softmax, именно такова:
def softmax(x): return exp(x) / exp(x).sum(dim=1, keepdim=True)Терминология: Экспоненциальная функция (exp): Буквально определяется как e * * x, где e - специальное число, приблизительно равное 2,718. Это обратная функция натурального логарифма. Обратите внимание, что exp всегда положительный, и он увеличивается очень быстро!
Давайте проверим, что softmax возвращает те же значения, что и sigmoid для первого столбца, и эти значения вычитаются из 1 для второго столбца:
sm_acts = torch.softmax(acts, dim=1)
sm_actstensor([[0.6025, 0.3975],
[0.5021, 0.4979],
[0.1332, 0.8668],
[0.9966, 0.0034],
[0.5959, 0.4041],
[0.3661, 0.6339]])
softmax -это мультикатегориальный эквивалент "сигмоида" - мы должны использовать его каждый раз, когда у нас есть более двух категорий, и сумма вероятностей категорий должны равняться 1. Мы часто используем его даже тогда, когда есть только две категории. Мы могли бы создать другие функции, которые обладают похожими свойствами, что все активации ннаходятся в диапазоне от 0 до 1 и суммируются до 1; однако ни одна другая функция не имеет такого же отношения к сигмоидной функции, которая, является гладкой и симметричной. Кроме того, вскоре мы увидим, что функция softmax хорошо работает с функцией потерь, которую мы рассмотрим в следующем разделе.
Если у нас есть три выходных активации, например, в нашем классификаторе медведей, вычисление softmax для одного изображения медведя будет выглядеть примерно так: <>.
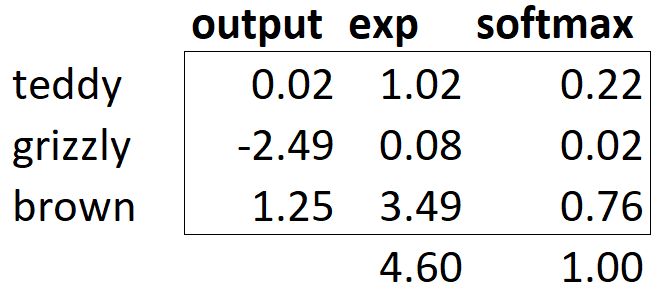
Что делает эта функция на практике? Взятие экспоненты гарантирует, что все наши числа положительны, а деление на сумму гарантирует, что у нас будет группа чисел, сумма которых равна 1. У экспоненты также есть приятное свойство: если одно из чисел в наших активациях x немного больше, чем другие, экспонента усилит это (так как она растет, ну ... экспоненциально), это означает, что число будет ближе к 1. Интуитивно функция softmax действительно хочет выбрать единственный класс среди других, поэтому она идеально подходит для обучения классификатора, когда каждое изображение имеет метку. (Это может быть неудобно когда ваша модель не распознает ни один из классов, которые она видела во время обучения. Но всё равно, вынужденна определять его по наибольшему числу. В этом случае лучше обучить модель, используя несколько двоичных выходных столбцов, каждый из которых использует сигмоидальную активацию.)
Softmax - это первая часть кросс-энтропийных потерь, вторая часть - это логарифмическая вероятность.
Логарифмическая вероятность
Когда мы вычисляли потери для нашего примера MNIST в предыдущей главе, мы использовали:
def mnist_loss(inputs, targets):
inputs = inputs.sigmoid()
return torch.where(targets==1, 1-inputs, inputs).mean()Точно так же, как мы перешли от sigmoid к softmax, нам нужно расширить функцию потерь — она должна классифицировать любое количество категорий (в данном случае у нас их 37). Значения после активации softmax, находятся между 0 и 1 и в сумме равны 1 для каждой строки в пакете предсказаний. Наши цели ( метки ) - целые числа от 0 до 36.
В двоичном случае мы использовали torch.where для выбора между двумя значениями. Становится значительно проще, когда мы рассматриваем двоичную классификацию как общую классификационную задачу с двумя категориями. Попробуем реализовать это в PyTorch. В нашем примере с синтетическими тройками и семерками, допустим, это наши метки:
targ = tensor([0,1,0,1,1,0])и это активации softmax:
sm_actstensor([[0.6025, 0.3975],
[0.5021, 0.4979],
[0.1332, 0.8668],
[0.9966, 0.0034],
[0.5959, 0.4041],
[0.3661, 0.6339]])
Для каждого элемента targ, с помощью тензорной индексации, выбрать соответствующий столбец sm_acts , например:
idx = range(6)
sm_acts[idx, targ]tensor([0.6025, 0.4979, 0.1332, 0.0034, 0.4041, 0.3661])
Чтобы точно увидеть, что здесь происходит, давайте объединим все столбцы в таблицу. Здесь первые два столбца - это наши активации, затем у нас есть цели, индекс строки и, наконец, результат, показанный непосредственно выше:
#hide_input
from IPython.display import HTML
df = pd.DataFrame(sm_acts, columns=["3","7"])
df['targ'] = targ
df['idx'] = idx
df['loss'] = sm_acts[range(6), targ]
t = df.style.hide_index()
#To have html code compatible with our script
html = t._repr_html_().split('</style>')[1]
html = re.sub(r'<table id="([^"]+)"\s*>', r'<table >', html)
display(HTML(html))| 3 | 7 | targ | idx | loss |
|---|---|---|---|---|
| 0.602469 | 0.397531 | 0 | 0 | 0.602469 |
| 0.502065 | 0.497935 | 1 | 1 | 0.497935 |
| 0.133188 | 0.866811 | 0 | 2 | 0.133188 |
| 0.996640 | 0.003360 | 1 | 3 | 0.003360 |
| 0.595949 | 0.404051 | 1 | 4 | 0.404051 |
| 0.366118 | 0.633882 | 0 | 5 | 0.366118 |
Взглянув на эту таблицу, можно увидеть, что конечный столбец можно вычислить, взяв столбцы targ и idx в качестве индексов в матрицу из двух столбцов, содержащую 3 и 7 столбцов. Вот что sm_acts[idx, тарг] делает.
Самое интересное здесь то, что это работает так же хорошо с более чем двумя колонками. Чтобы увидеть это, рассмотрим, что произойдет, если мы добавим столбец активации для каждой цифры (от 0 до 9), а targ будет содержать число от 0 до 9. Пока сумма столбцов активации равна 1 (если использовать softmax) функция потерь покажет, насколько верно мы предсказываем каждую цифру.
Мы выбираем потерю только из столбца, содержащего правильную метку. Нам не нужно рассматривать другие столбцы, потому что по определению softmax они в сумме дают 1 , минус активация правильной метке. Поэтому максимально высокая активация для правильной метки означает, что мы уменьшаем активации остальных столбцов.
PyTorch предоставляет функцию, которая делает точно то же самое, что и sm_acts[range(n), targ] (за исключением того, что она принимает отрицательное значениеа), называемую nll_loss (NLL означает отрицательное логарифмическое правдоподобие):
-sm_acts[idx, targ]tensor([-0.6025, -0.4979, -0.1332, -0.0034, -0.4041, -0.3661])
F.nll_loss(sm_acts, targ, reduction='none')tensor([-0.6025, -0.4979, -0.1332, -0.0034, -0.4041, -0.3661])
Несмотря на название, эта функция PyTorch не ведет журнал. Почему так, узнаем в следующем разделе, но сначала посмотрим, для чего полезно использование логарифма.
Вычисление логарифма
Функция, которую мы видели в предыдущем разделе, работает как функция потерь, но мы можем сделать ее немного лучше. Проблема в том, что мы используем вероятности, и вероятности не могут быть меньше 0 или больше 1. Это означает, что нашу модель не волнует, прогнозирует ли она 0,99 или 0,999. Действительно, эти цифры так близки друг к другу, но 0,999 в 10 раз увереннее 0,99. Итак, мы хотим преобразовать наши числа в диапазоне между 0 и 1, между отрицательной бесконечностью и 0. Существует математическая функция, которая делает именно это: логарифм (доступен как torch.log). Он не определен для чисел меньше 0 и выглядит следующим образом:
plot_function(torch.log, min=0,max=4)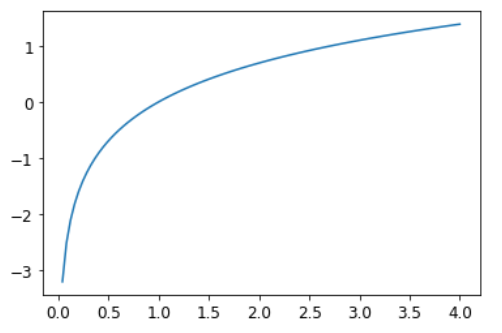
Логарифмическая функция имеет следующую идентичность:
y = b**a a = log(y,b) В этом случае мы предполагаем, что log(y,b)возвращает log y по основанию b . Однако PyTorch фактически не определяет 'log' таким образом: 'log' в Python использует ,в качестве основания, специальный номер e (2.718...) .
Возможно, логарифм - это то, о чем вы не задумывались последние 20 лет или около того. Но это математическая идея, которая будет очень важна для многих вещей в глубоком обучении, поэтому сейчас самое время освежить свою память. Главное, что нужно знать о логарифмах, - это соотношение: Возможно, логарифм-это то, о чем вы не думали в течение последних 20 лет. Но это математическая идея, которая будет очень важна для многих вещей в глубоком обучении, так что сейчас самое время освежить вашу память. Ключевая вещь, которую нужно знать о логарифмах, - это соотношение:
log(a*b) = log(a)+log(b)
Это означает, что логарифмы увеличиваются линейно, когда основной сигнал увеличивается экспоненциально или мультипликативно. Это используется, например, в шкале силы землетрясения Рихтера и шкале уровней шума в дБ. Его также часто используют на финансовых графиках, где мы хотим более четко показать совокупные темпы роста. Ученые-информатики любят использовать логарифмы, потому что это означает, что умножение, которое может создавать действительно очень большие и маленькие числа, можно заменить сложением, которое гораздо реже приводит к масштабам, с которыми трудно справиться нашим компьютерам.
s: Журналы любят не только компьютерщики! Пока не появились компьютеры, инженеры и ученые пользовались специальной линейкой, называемой "логарифмической линейкой", которая делала умножение путем сложения логарифмов. Логарифмы широко используются в физике, для умножения очень больших или очень малых чисел и во многих других областях.
Среднее значение положительного или отрицательного логарифма вероятностей (в зависимости от того, правильный это класс или неправильный) дает нам отрицательную логарифмическую потерю. В PyTorch nll_loss предполагается, что вы уже взяли логарифм softmax.
предупреждение: Будьте осторожны: nll в nll_lossрасшифровывается как "отрицательная логарифмическая вероятность", но на самом деле он вообще не принимает логарифм ! Он предполагает, что вы логарифм уже взяли. В PyTorch есть функция log_softmax, которая сочетает в себе log и softmax. nll_loss предназначен для использования после log_softmax.
Когда мы сначала берем softmax, а затем логарифмическую вероятность этого, эта комбинация называется кросс-энтропийной потерей . В PyTorch это доступно как nn.CrossEntropyLoss (что, на практике, фактически делает log_softmax, а затем nll_loss):
loss_func = nn.CrossEntropyLoss()Как видите, это класс. Его создание дает вам объект, который ведет себя как функция:
loss_func(acts, targ)tensor(1.8045)
Все функции потери PyTorch предоставляются в двух формах, только что показанном выше классе, а также в простой функциональной форме, доступной в пространстве имен F:
F.cross_entropy(acts, targ)tensor(1.8045)
Любая из них прекрасно работает и может быть использован в любой ситуации. Мы заметили, что большинство людей склонны использовать версию класса, и она чаще используется в официальных документах и примерах PyTorch, поэтому мы тоже будем использовать ее.
По умолчанию функции потерь PyTorch принимают среднее значение потерь всех элементов. Вы можете использовать reduction='none', чтобы отключить это:
nn.CrossEntropyLoss(reduction='none')(acts, targ)tensor([0.5067, 0.6973, 2.0160, 5.6958, 0.9062, 1.0048])
субъект: Интересная особенность кросс-энтропийных потерь появляется, когда мы рассматриваем их градиент. Градиент cross_entropy(a,b) - это просто softmax(a)-b. Поскольку softmax(a) является окончательной активацией модели, это означает, что градиент пропорционален разнице между предсказанием и целью. Это то же самое, что среднеквадратичная ошибка в регрессии (при условии, что нет конечной функции активации, такой как добавленная y_range), поскольку градиент (a-b)**2равен 2*(a-b) и он линейный, это означает, что мы не увидим резких скачков или экспоненциального увеличения градиентов, что должно привести к более плавному обучению моделей.
Теперь мы увидели все части, скрытые за нашей функцией потерь. Это дает представление о том, хорошо (или плохо) работает наша модель,но это никак не помогает нам узнать, действительно ли она хороша. Давайте теперь посмотрим, как интерпретировать прогнозы нашей модели.
Интерпретация модели
Очень сложно интерпретировать функции потерь напрямую, потому что они предназначены для того, чтобы компьютеры могли различать и оптимизировать, а не для того, что люди могут понять. Вот почему у нас есть метрики. Они не используются в процессе оптимизации, а просто помогают нам, бедным людям, понять, что происходит. В этом случае наша точность уже выглядит неплохо! Так где же мы ошибаемся?
Мы видели в < >, что можем использовать матрицу путаницы, чтобы увидеть, где наша модель работает хорошо, а где плохо:
#width 600
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix(figsize=(12,12), dpi=60)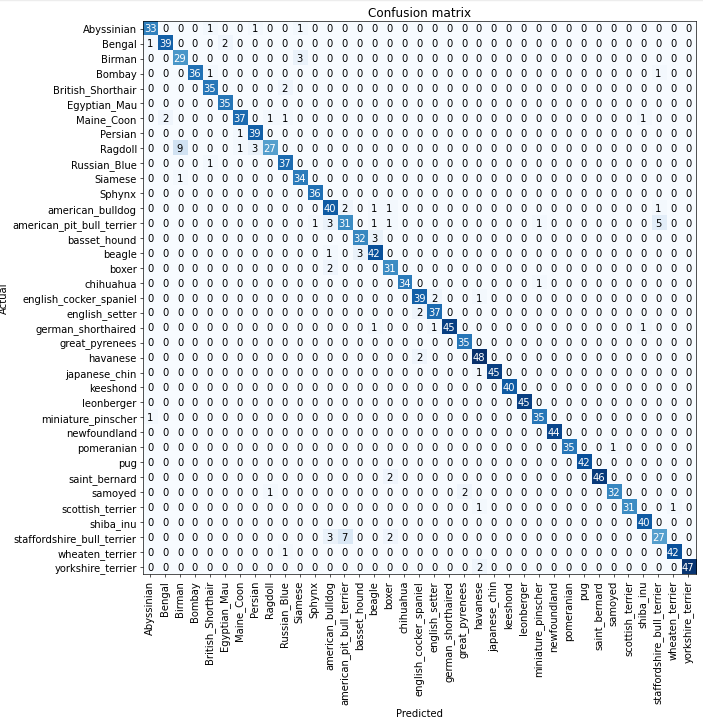
В данном случае очень трудно прочитать матрицу путаницы. У нас 37 разных пород домашних животных, что означает, что у нас есть записи 37 × 37 в этой гигантской матрице! Вместо этого мы можем использовать метод most_confused, который просто показывает нам ячейки матрицы путаницы с наиболее неправильными предсказаниями (здесь, по крайней мере, с 5 или более):
interp.most_confused(min_val=5)[('Ragdoll', 'Birman', 9),
('staffordshire_bull_terrier', 'american_pit_bull_terrier', 7),
('american_pit_bull_terrier', 'staffordshire_bull_terrier', 5)]
Поскольку мы не являемся экспертами по породам домашних животных, нам трудно понять, отражают ли эти категориальные ошибки реальные трудности в распознавании пород. Итак, снова обратимся к Google. Небольшой поиск в Google говорит нам, что наиболее распространенные ошибки категорий, показанные здесь, на самом деле являются различиями между породами, с которыми иногда не соглашаются даже опытные заводчики. Так что это дает нам уверенность в том, что мы на правильном пути.
Похоже, у нас хорошая база. Что мы можем сделать сейчас, чтобы сделать её еще лучше?
Улучшение нашей модели
Теперь мы рассмотрим ряд методов, позволяющих улучшить обучение нашей модели и сделать ее лучше. При этом мы расскажем немного больше о трансферном обучении и о том, как максимально точно настроить нашу предварительно обученную модель, не нарушая предварительно обученных весов.
Первое, что нам нужно - это скорость обучения.Так как же нам выбрать её? Fastai предоставляет инструмент для этого.
Средство поиска скорости обучения
Одна из самых важных вещей, при обучении модели, - это убедиться, что у нас правильная скорость обучения. Если наша скорость обучения слишком низкая, для обучения может потребоваться много-много эпох. Это не только напрасная трата времени, но также может привести к проблемам с переобучением, потому что каждый раз, когда мы выполняем полный проход данных, мы даем нашей модели возможность запомнить их.
Так что давайте просто сделаем нашу скорость обучения высокой, верно? Конечно, давайте попробуем и посмотрим, что получится:
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1, base_lr=0.1)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 2.665226 | 5.128072 | 0.441813 | 00:34 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 4.260814 | 3.084894 | 0.834235 | 00:42 |
Это не выглядит хорошо. Вот что произошло. Оптимизатор шагнул в правильном направлении, но шагнул так далеко, что полностью превысил минимальную потерю. Повторяя это несколько раз, он становится все дальше и дальше, а не ближе и ближе!
Что мы делаем, чтобы найти идеальную скорость обучения - не слишком высокую и не слишком низкую? В 2015 году исследователь Лесли Смит (Leslie Smith) придумал блестящую идею, названную поисковиком скорости обучения . Его идея заключалась в том, чтобы начать с очень, очень маленькой скорости обучения. Мы используем это для одного мини-пакета, затем выясняем, какие потери будут, а затем увеличиваем скорость обучения на некоторый процент (например, удваивая ее каждый раз). Затем еще один мини-пакет, отслеживаем потери и снова удваиваем скорость обучения. Мы продолжаем делать это до тех пор, пока потеря не станет хуже. Это тот момент, когда мы знаем, что зашли слишком далеко. Затем мы выбираем скорость обучения немного ниже этой точки. Наш совет - выбрать:
- На один порядок меньше, чем при достижении минимальной потери (т.е. минимальной, деленной на 10)
- Последняя точка, когда потери явно снижались
Поисковик скорости обучения вычисляет эти точки на кривой, чтобы помочь вам. Оба эти правила обычно дают примерно одно и то же значение. В первой главе мы не указывали скорость обучения, используя значение по умолчанию из библиотеки fastai (1e-3):
learn = cnn_learner(dls, resnet34, metrics=error_rate)
lr_min,lr_steep = learn.lr_find()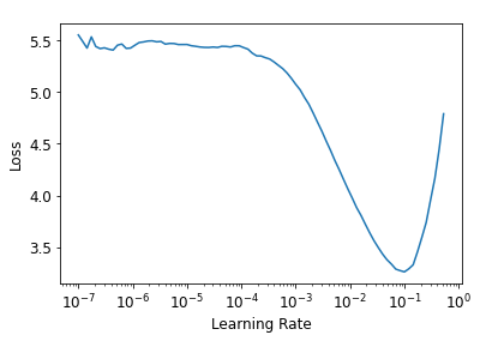
print(f"Minimum/10: {lr_min:.2e}, steepest point: {lr_steep:.2e}")Minimum/10: 1.00e-02, steepest point: 4.37e-03
Видно, что в диапазоне от 1e-6 до 1e-3 на самом деле ничего не происходит и модель не тренируется. Затем потеря начинает уменьшаться до тех пор, пока не достигнет минимума, а затем снова увеличивается. Мы не хотим, чтобы уровень обучения превышал 1e-1, так как это даст обучение, которое расходится, как раньше (вы можете попробовать сами), но 1e-1 уже слишком много: на этом этапе мы вышли из периода, когда потери неуклонно снижались.
На этом графике оказывается, что скорость обучения около 3e-3 была бы подходящей, поэтому на ней и остановимся:
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(2, base_lr=3e-3)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.317766 | 0.321528 | 0.100812 | 00:35 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.552802 | 0.301743 | 0.081191 | 00:43 |
| 1 | 0.327349 | 0.205416 | 0.064276 | 00:44 |
Примечание: Логарифмическая шкала: График поиска скорости обучения имеет логарифмическую шкалу, поэтому средняя точка между 1e-3 и 1e-2 находится между 3e-3 и 4e-3. Нам важно определить порядок величины скорости обучения.
Интересно, что средство поиска скорости обучения было обнаружено только в 2015 году, а нейронные сети разрабатывались с 1950-х годов. Все это время поиск хорошей скорости обучения был, пожалуй, самой важной и сложной задачей для практиков. Решение не требует продвинутой математики, гигантских вычислительных ресурсов, огромных наборов данных или чего-либо еще, что сделало бы его недоступным для любого исследователя. Кроме того, Лесли Смит не работал в какой-то эксклюзивной лаборатории Кремниевой долины, а работал военно-морским исследователем. Все это означает: революционная работа в области глубокого обучения абсолютно не требует доступа к обширным ресурсам, элитным командам или передовым математическим идеям. Впереди еще много работы, требующей лишь немного здравого смысла, творчества и упорства.
Теперь, когда у нас есть хорошая скорость обучения для обучения нашей модели, давайте посмотрим, как мы можем точно настроить веса предварительно обученной модели.
Разморозка и перенос обучения
Мы кратко обсудили в <>, как работает трансфертное обучение. Мы видели, что основная идея состоит в том, что предварительно подготовленная модель, обученная потенциально на миллионах данных (таких как ImageNet ), точно настроена для какой-то другой задачи. Но что это значит на самом деле? Теперь мы знаем, что сверточная нейронная сеть состоит из множества линейных слоев с нелинейной функцией активации между каждой парой, за которыми следуют один или несколько конечных линейных слоев с функцией активации, такой как softmax. Последний линейный слой использует матрицу, так что выходной размер совпадает с количеством классов в нашей модели (при условии, что мы проводим классификацию).
Этот последний линейный слой вряд ли будет полезен для нас при тонкой настройке параметров трансферного обучения, поскольку он специально разработан для классификации категорий в исходном наборе данных (таких как ImageNet ). Поэтому, когда мы выполняем перенос обучения, мы удаляем его и заменяем новым линейным слоем с правильным количеством выходов для нашей задачи (в этом случае было бы 37 активаций).
Этот добавленный линейный слой будет иметь совершенно случайные веса. Следовательно, наша модель до точной настройки дает полностью случайные результаты. Но это не значит, что это полностью случайная модель! Все слои, предшествующие последнему, были тщательно обучены, чтобы в целом хорошо справляться с задачами классификации изображений. Как мы видели на изображениях из статьи Цейлера и Фергуса, первые несколько слоев кодируют очень общие концепции, такие как поиск градиентов и краев, а более поздние слои кодируют концепции, которые очень полезны для нас, например, поиск глазных яблок или шерсти.
Мы хотим обучить модель таким образом, чтобы позволить ей запоминать все эти общие, полезные идеи из предварительно обученной модели, использовать их для решения нашей конкретной задачи (классифицировать породы домашних животных) и корректировать их только так, как это требуется для нашей специфики.
Наша задача состоит в том, чтобы заменить случайные веса в наших добавленных линейных слоях весами, которые правильно выполняют задачу (классификация пород домашних животных), не нарушая тщательно подготовленные веса в других слоях.Существует очень простой трюк: скажите оптимизатору, чтобы он обновлял только веса в добавленных нами слоях. Не меняйте вообще веса в остальной части нейронной сети. Это называется замораживанием предварительно обученных слоев.
При создании модели из предварительно обученной сети fastai автоматически замораживает все предварительно обученные слои. Когда мы вызываем метод fine_tune fastai делает две вещи:
- Тренирует добавленные слои для одной эпохи с замораживанием всех остальных слоев
- Размораживает все слои и тренирует их все на требуемое количество эпох
Хотя это разумный подход по умолчанию, вполне вероятно, что для вашего конкретного набора данных вы можете получить лучшие результаты, сделав по-другому. Метод fine_tune имеет ряд параметров, которые вы можете использовать для изменения его поведения, вызывая базовые методы напрямую. Помните, что вы можете увидеть исходный код метода, используя следующий синтаксис:
learn.fine_tune??
Давайте попробуем сделать это вручную. Сначала мы будем тренировать добавленные слои для трех эпох, используя fit_one_cycle - это предлагаемый способ обучения моделей без использования fine_tune. fit_one_cycle начинает обучение с низкой скоростью , постепенно увеличивая ее для первого этапа, а затем постепенно уменьшая ее для последнего этапа обучения.
learn.fine_tune??[0;31mSignature:[0m [0mlearn[0m[0;34m.[0m[0mfine_tune[0m[0;34m([0m[0;34m[0m [0;34m[0m [0mepochs[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mbase_lr[0m[0;34m=[0m[0;36m0.002[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mfreeze_epochs[0m[0;34m=[0m[0;36m1[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mlr_mult[0m[0;34m=[0m[0;36m100[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mpct_start[0m[0;34m=[0m[0;36m0.3[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mdiv[0m[0;34m=[0m[0;36m5.0[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mlr_max[0m[0;34m=[0m[0;32mNone[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mdiv_final[0m[0;34m=[0m[0;36m100000.0[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mwd[0m[0;34m=[0m[0;32mNone[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mmoms[0m[0;34m=[0m[0;32mNone[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mcbs[0m[0;34m=[0m[0;32mNone[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mreset_opt[0m[0;34m=[0m[0;32mFalse[0m[0;34m,[0m[0;34m[0m [0;34m[0m[0;34m)[0m[0;34m[0m[0;34m[0m[0m [0;31mSource:[0m [0;34m@[0m[0mpatch[0m[0;34m[0m [0;34m[0m[0;34m@[0m[0mdelegates[0m[0;34m([0m[0mLearner[0m[0;34m.[0m[0mfit_one_cycle[0m[0;34m)[0m[0;34m[0m [0;34m[0m[0;32mdef[0m [0mfine_tune[0m[0;34m([0m[0mself[0m[0;34m:[0m[0mLearner[0m[0;34m,[0m [0mepochs[0m[0;34m,[0m [0mbase_lr[0m[0;34m=[0m[0;36m2e-3[0m[0;34m,[0m [0mfreeze_epochs[0m[0;34m=[0m[0;36m1[0m[0;34m,[0m [0mlr_mult[0m[0;34m=[0m[0;36m100[0m[0;34m,[0m[0;34m[0m [0;34m[0m [0mpct_start[0m[0;34m=[0m[0;36m0.3[0m[0;34m,[0m [0mdiv[0m[0;34m=[0m[0;36m5.0[0m[0;34m,[0m [0;34m**[0m[0mkwargs[0m[0;34m)[0m[0;34m:[0m[0;34m[0m [0;34m[0m [0;34m"Fine tune with `freeze` for `freeze_epochs` then with `unfreeze` from `epochs` using discriminative LR"[0m[0;34m[0m [0;34m[0m [0mself[0m[0;34m.[0m[0mfreeze[0m[0;34m([0m[0;34m)[0m[0;34m[0m [0;34m[0m [0mself[0m[0;34m.[0m[0mfit_one_cycle[0m[0;34m([0m[0mfreeze_epochs[0m[0;34m,[0m [0mslice[0m[0;34m([0m[0mbase_lr[0m[0;34m)[0m[0;34m,[0m [0mpct_start[0m[0;34m=[0m[0;36m0.99[0m[0;34m,[0m [0;34m**[0m[0mkwargs[0m[0;34m)[0m[0;34m[0m [0;34m[0m [0mbase_lr[0m [0;34m/=[0m [0;36m2[0m[0;34m[0m [0;34m[0m [0mself[0m[0;34m.[0m[0munfreeze[0m[0;34m([0m[0;34m)[0m[0;34m[0m [0;34m[0m [0mself[0m[0;34m.[0m[0mfit_one_cycle[0m[0;34m([0m[0mepochs[0m[0;34m,[0m [0mslice[0m[0;34m([0m[0mbase_lr[0m[0;34m/[0m[0mlr_mult[0m[0;34m,[0m [0mbase_lr[0m[0;34m)[0m[0;34m,[0m [0mpct_start[0m[0;34m=[0m[0mpct_start[0m[0;34m,[0m [0mdiv[0m[0;34m=[0m[0mdiv[0m[0;34m,[0m [0;34m**[0m[0mkwargs[0m[0;34m)[0m[0;34m[0m[0;34m[0m[0m [0;31mFile:[0m /pt/pt_ai/lib/python3.6/site-packages/fastai/callback/schedule.py [0;31mType:[0m method
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(3, 3e-3)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.118055 | 0.358634 | 0.110961 | 00:35 |
| 1 | 0.546789 | 0.230265 | 0.071042 | 00:37 |
| 2 | 0.332612 | 0.222686 | 0.064953 | 00:39 |
Затем разморозим модель:
python learn.unfreeze()
и снова запустить lr_find, потому что наличие большего количества слоев и их весов, которые уже были обучены в течение трех эпох, означает, что наша ранее найденная скорость обучения больше не подходит:
learn.unfreeze()SuggestedLRs(lr_min=7.585775847473997e-08, lr_steep=6.309573450380412e-07)
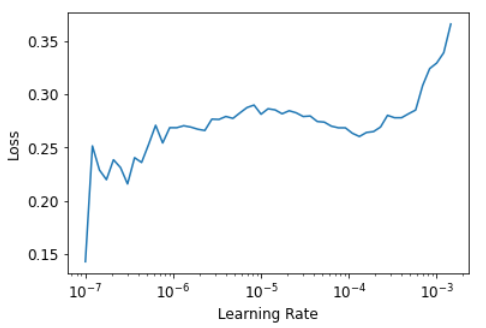
Обратите внимание, что график немного отличается от того, когда у нас были случайные веса: у нас нет того резкого спуска, который указывает на то, что модель обучается. Это потому, что наша модель уже обучена. Здесь мы имеем плоскую область перед резким увеличением, и мы должны взять точку задолго до этого резкого увеличения - например, 1е-5. Точка с максимальным градиентом - это не то, что мы ищем здесь, и ее следует игнорировать.
Давайте тренироваться с подходящей скоростью обучения:
learn.fit_one_cycle(6, lr_max=1e-5)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.263168 | 0.213162 | 0.063599 | 00:43 |
| 1 | 0.243711 | 0.215372 | 0.065629 | 00:43 |
| 2 | 0.227926 | 0.204228 | 0.058187 | 00:43 |
| 3 | 0.223090 | 0.202671 | 0.062246 | 00:45 |
| 4 | 0.187064 | 0.198326 | 0.060217 | 00:46 |
| 5 | 0.188365 | 0.199288 | 0.059540 | 00:46 |
Это немного улучшило нашу модель, но мы можем сделать еще больше. Самые глубокие слои нашей предварительно обученной модели, возможно, не нуждаются в такой высокой скорости обучения, как последние, поэтому мы, вероятно, должны использовать разные скорости обучения для них - это известно как использование дискриминационной скорости обучения.
Дискриминационная скорость обучения
Даже после того, как мы разморозили веса, нам всё ещё важна предварительно обученная модель. Поэтому мы не можем позволить себе такую же высокую скорость обучения как на нашем добавленно слое.Даже обученном на нескольких эпохах Помните, что заранее подготовленные модели были обучены на протяжении сотен эпох, на миллионах изображений.
Кроме того, помните ли вы изображения, которые мы видели в < > и которые показывают, чему учится каждый слой?Первый слой изучает очень простые основы, такие как детекторы краев и градиентов; они полезны практически для любой задачи. Более поздние слои изучают гораздо более сложные понятия, такие как "глаз" и "закат", которые могут вообще не пригодиться в вашей задаче (например, вы классифицируете модели автомобилей). Поэтому имеет смысл позволить более поздним слоям настраиваться быстрее, чем более ранним.
Поэтому подход fastai по умолчанию заключается в использовании дискриминационных скоростей обучения. Как и многие хорошие идеи в области глубокого обучения, он чрезвычайно прост: используйте более низкую скорость обучения для ранних слоев нейронной сети и более высокую скорость обучения для более поздних слоев (и особенно случайно добавленных слоев). Идея основана на разработках Джейсона Йосински, который показал в 2014 году, что при трансферном обучении различные слои нейронной сети должны тренироваться с разной скоростью, как показано в <>.
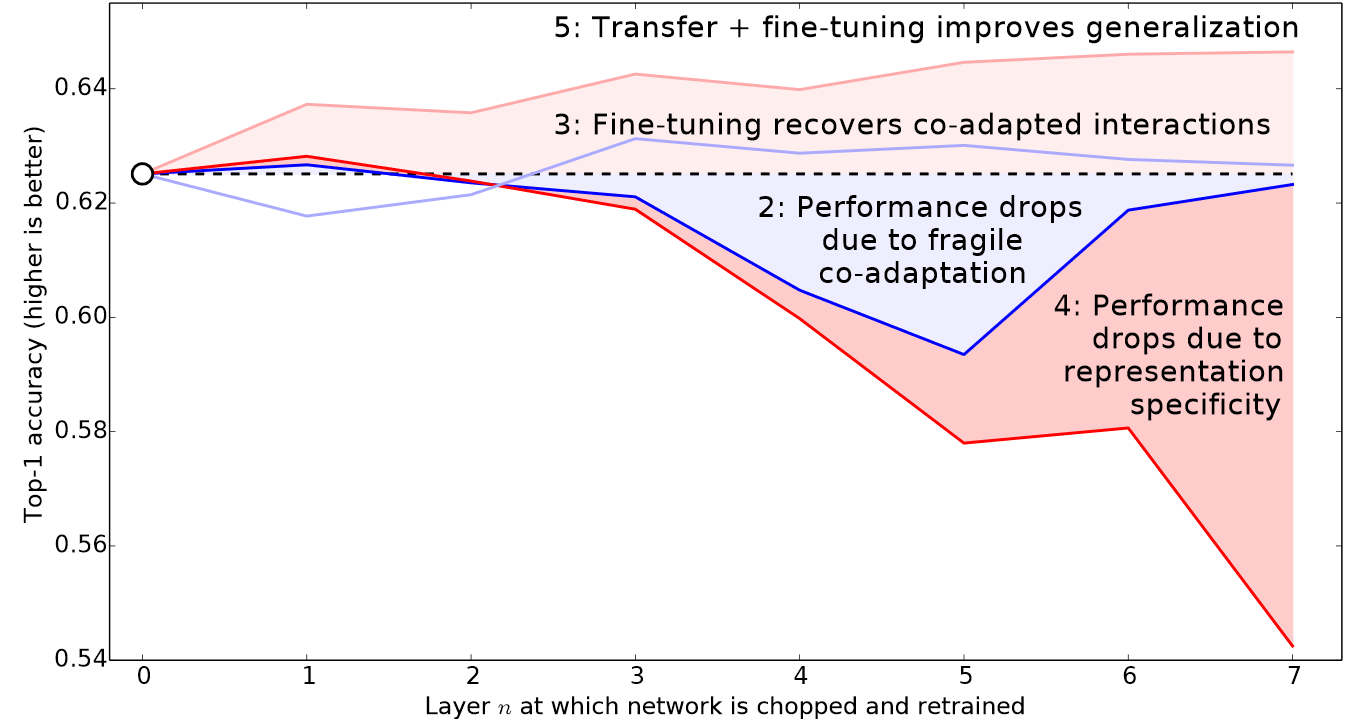
fastai позволяет передавать срез объекта Python в любом месте, где ожидается скорость обучения. Первое переданное значение будет скоростью обучения в самом раннем слое нейронной сети, а второе - скоростью обучения в последнем слое. Промежуточные слои будут иметь скорости обучения, которые мультипликативно равноудалены на этом диапазоне. Давайте воспользуемся этим подходом, чтобы повторить предыдущее обучение, но на этот раз мы установим самый низкий уровень нашей сети на скорость обучения 1e-6; другие слои будут масштабироваться до 1e-4. Давайте немного потренируемся и посмотрим что получится:
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(3, 3e-3)
learn.unfreeze()
learn.fit_one_cycle(12, lr_max=slice(1e-6,1e-4))| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.150967 | 0.345679 | 0.105548 | 00:35 |
| 1 | 0.518034 | 0.230182 | 0.073072 | 00:36 |
| 2 | 0.316568 | 0.196914 | 0.062923 | 00:37 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.283483 | 0.198676 | 0.060217 | 00:43 |
| 1 | 0.251810 | 0.191843 | 0.062246 | 00:43 |
| 2 | 0.246457 | 0.190149 | 0.057510 | 00:44 |
| 3 | 0.222310 | 0.176923 | 0.061570 | 00:45 |
| 4 | 0.203167 | 0.171902 | 0.052774 | 00:48 |
| 5 | 0.165781 | 0.170654 | 0.056157 | 00:48 |
| 6 | 0.160764 | 0.172639 | 0.055480 | 00:47 |
| 7 | 0.153904 | 0.172199 | 0.055480 | 00:48 |
| 8 | 0.138313 | 0.170113 | 0.054127 | 00:49 |
| 9 | 0.123947 | 0.170578 | 0.054804 | 00:49 |
| 10 | 0.119653 | 0.165557 | 0.052774 | 00:49 |
| 11 | 0.124251 | 0.169486 | 0.052097 | 00:53 |
Теперь тонкая настройка работает отлично!
График потерь при обучении и валидации:
learn.recorder.plot_loss()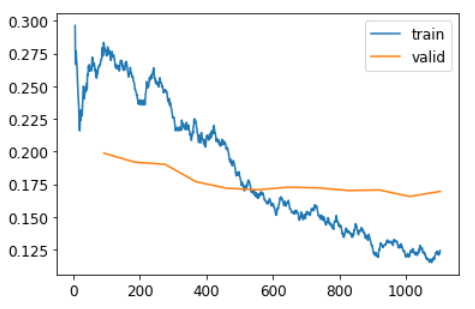
Как вы можете видеть, ошибка на обучении становится все лучше и лучше. Но в конечном итоге улучшение ошибки валидации замедляется, а иногда даже ухудшается! Это точка, в которой модель начинает перестраиваться. В частности, модель становится слишком самоуверенной в своих предсказаниях. Но это не значит, что она обязательно становится менее точной. Взгляните на таблицу результатов обучения за каждую эпоху, и вы увидите, что точность продолжает улучшаться, даже когда ошибка валидации становится хуже. В конце концов, важна ваша точность или, в более общем смысле, выбранные вами показатели, а не потери. Потеря - это просто функция, которую мы дали компьютеру, чтобы помочь нам оптимизировать модель.
Еще одно решение, которое вы должны принять при обучении модели, - это как долго тренироваться. Мы рассмотрим это в следующий раз.
Выбор количества эпох
При выборе эпох обучения, вы часто понимаете, что ограничены временем, а не обобщением и точностью. Ваш первый выбор количества эпох должен состоять из того количества времени, которое вы можете ждать , чтобы получить результаты. Затем стоит оценить свои метрики , посмотрить на графики потерь при обучении и проверке, и если вы видите, что они все еще улучшаются то стоить продолжить обучение.
С другой стороны, вы вполне можете увидеть, что выбранные вами показатели действительно ухудшаются в конце обучения. Мы оцениваем не только потери при проверке, но и реальные показатели.Наша функция потерь - это просто то, что помогает нашему оптимизатору. На самом деле это не то, о чем мы заботимся на практике.
До тех пор, пока не было одноциклового обучения, было очень распространено сохранять модель в конце каждой эпохи, а затем выбирать ту модель, которая имела наилучшую точность из всех моделей, сохраненных в каждую эпоху. Это называется ранней остановкой . Если вы обнаружите, что у вас переобучение, вам действительно следует переобучить свою модель с нуля и выбрать общее количество эпох в зависимости от того, где были получены лучшие результаты.
Если у вас есть время для обучения большему количеству эпох, вы можете вместо этого использовать это время для обучения большего количества параметров, то есть использовать более глубокую архитектуру.
Более глубокие архитектуры
В общем, модель с большим количеством параметров может более точно моделировать ваши данные. (Есть много-много предостережений в отношении этого обобщения, и это зависит от специфики используемых вами архитектур, но на данный момент это разумное практическое правило.) Для большинства архитектур, которые мы увидим в этой книге , вы можете создавать их более крупные версии, просто добавляя дополнительные слои. Поскольку мы хотим использовать предварительно обученные модели, нам нужно убедиться, что мы выбрали ряд слоев, которые уже были предварительно обучены.
Вот почему на практике архитектуры, как правило, представлены в небольшом количестве вариантов. Например, архитектура ResNet, которую мы используем в этой главе, поставляется в вариантах с 18, 34, 50, 101 и 152 уровнями, предварительно обученными на ImageNet. Более крупная (больше слоев и параметров; иногда описываемая как «емкость» модели) версия ResNet всегда сможет дать нам лучшие потери при обучении, но она может больше пострадать от переобучения.
В целом, более крупная модель способна лучше фиксировать реальные взаимосвязи в ваших данных, а также фиксировать и запоминать конкретные детали ваших отдельных изображений.
Однако для использования более глубокой модели потребуется больше ОЗУ графического процессора, поэтому вам может потребоваться уменьшить размер пакетов, чтобы избежать ошибки нехватки памяти . Это происходит, когда вы пытаетесь слишком много уместить в своем графическом процессоре и выглядит так:
Cuda runtime error: out of memory
В этом случае вам, возможно, придется перезагрузить ноутбук. Чтобы решить эту проблему, используйте пакет меньшего размера, что означает передачу меньших групп изображений. Вы можете передать нужный размер пакета вызову, создав свой DataLoaders с помощью bs=.
Другой недостаток более глубоких архитектур заключается в том, что их обучение занимает больше времени. Один из методов, который может значительно ускорить процесс, - это тренировка со смешанной точностью . Это относится к использованию менее точных чисел (полуточная плавающая точка, также называемая fp16) там, где это возможно во время обучения. Когда мы пишем эти слова в начале 2020 года, почти все современные графические процессоры NVIDIA поддерживают специальную функцию под названием "тензорные ядра", которая может значительно ускорить обучение нейронных сетей в 2-3 раза. Они также требуют гораздо меньше памяти GPU. Чтобы включить эту функцию в fastai, просто добавьте to_fp16 () после создания вашего Learner(вам также нужно импортировать модуль).
Вы не можете заранее знать, какая архитектура лучше всего подходит для вашей конкретной проблемы - вам нужно попробовать, потренироваться. Так что давайте теперь попробуем ResNet-50 со смешанной точностью:
from fastai.callback.fp16 import *
learn = cnn_learner(dls, resnet50, metrics=error_rate).to_fp16()
learn.fine_tune(6, freeze_epochs=3)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.304921 | 0.271969 | 0.089986 | 00:37 |
| 1 | 0.609828 | 0.294031 | 0.098106 | 00:44 |
| 2 | 0.450777 | 0.281802 | 0.083221 | 00:45 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.254730 | 0.229946 | 0.066306 | 00:52 |
| 1 | 0.309989 | 0.324002 | 0.098782 | 00:51 |
| 2 | 0.237493 | 0.235913 | 0.073072 | 00:51 |
| 3 | 0.158982 | 0.194529 | 0.058187 | 00:49 |
| 4 | 0.091783 | 0.167944 | 0.048714 | 00:49 |
| 5 | 0.060390 | 0.162074 | 0.047361 | 00:50 |
learn.recorder.plot_loss()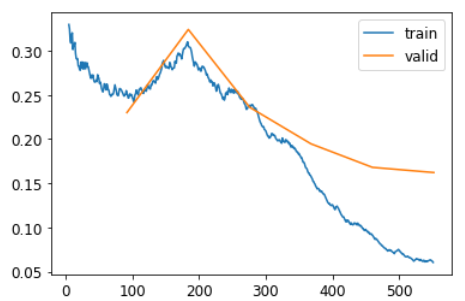
Вы увидите, что здесь мы вернулись к использованию fine_tune, это так удобно! Мы можем передать freeze_epochs, чтобы сказать fastai, сколько эпох нужно тренироваться, пока он заморожен. Он автоматически изменит скорость обучения соответствующим образом для большинства наборов данных.
В этом случае мы не видим явного выигрыша от более глубокой модели. Это полезно помнить - большие модели не обязательно являются лучшими моделями для вашего конкретного случая! Обязательно попробуйте небольшие модели, прежде чем приступать к масштабированию.
Вывод
В этой главе вы узнали несколько важных практических советов, как для подготовки ваших данных изображения к моделированию (предварительная оценка, сводка блока данных), так и для подгонки модели (поиск скорости обучения, размораживание, дискриминационная скорость обучения, установка количества эпох и использование более глубокие архитектуры). Использование этих инструментов поможет вам быстрее и точнее создавать модели изображений.
Мы также обсудили потерю кросс-энтропии. На эту часть книги стоит потратить много времени. На практике вам вряд ли понадобится реализовывать кросс-энтропийную потерю с нуля, но очень важно, чтобы вы понимали входные и выходные данные этой функции, потому что она (или ее вариант, как мы увидим в следующая глава) используется почти в каждой модели классификации. Поэтому, когда вы хотите отладить модель, или запустить модель в производство, или повысить точность модели, вам нужно будет иметь возможность посмотреть на ее активации и потери и понять, что происходит и почему. Вы не сможете сделать это правильно, если не понимаете свою функцию потерь.
Если кросс-энтропийная потеря еще не дошла до вас, не волнуйтесь - вы добьетесь цели! Во-первых, вернитесь к последней главе и убедитесь, что вы действительно понимаете mnist_loss. Затем постепенно прорабатывайте ячейки ноутбука этой главы, где мы шаг за шагом перебираем каждый фрагмент перекрестной энтропии. Убедитесь, что вы понимаете, что делает каждый расчет и почему. Попробуйте сами создать несколько небольших тензоров и передать их функциям, чтобы посмотреть, что они вернут.
Помните: выбор, сделанный при реализации потери кросс-энтропии, - не единственный возможный выбор, который можно было сделать. Точно так же, как когда мы смотрели на регрессию, мы могли выбирать между среднеквадратической ошибкой и средней абсолютной разностью (L1). Если у вас есть другие идеи относительно возможных функций, которые, по вашему мнению, могут работать, вы можете попробовать их в ноутбуке этой главы! (Однако справедливое предупреждение: вы, вероятно, обнаружите, что модель будет медленнее обучаться и быть менее точной. Это связано с тем, что градиент кросс-энтропийных потерь пропорционален разнице между активацией и целью, поэтому SGD всегда получает хорошо масштабированный шаг для весов.)
Опросник
- Почему мы сначала изменяем размер до большого размера на ЦП, а затем до меньшего размера на графическом процессоре?
- Если вы не знакомы с регулярными выражениями, найдите учебник по регулярным выражениям и некоторые наборы задач и выполните их. Посмотрите предложения на сайте книги.
- Какими двумя способами чаще всего предоставляются данные для большинства наборов данных глубокого обучения?
- Поищите документацию L и попробуйте использовать несколько новых методов, которые она добавляет.
- Посмотрите документацию по pathlib модулю Python и попробуйте использовать несколько методов Path класса.
- Приведите два примера того, как преобразования изображений могут ухудшить качество данных.
- Какой метод предоставляет fastai для просмотра данных в DataLoaders?
- Какой метод предлагает fastai для отладки DataBlock?
- Следует ли вам отложить обучение модели до тех пор, пока вы полностью не очистите свои данные?
- Какие две составляющие объединены в потерю кросс-энтропии в PyTorch?
- Какие два свойства активации обеспечивает softmax? Почему это важно?
- Когда вы можете захотеть, чтобы ваши активации не имели этих двух свойств?
- Вычислите столбцы exp и softmax< > самостоятельно (например, в электронной таблице, с помощью калькулятора или в записной книжке).
- Почему мы не можем использовать torch.where функцию потерь для наборов данных, в которых наша метка может иметь более двух категорий?
- Какое значение имеет log(-2)? Почему?
- Каковы два хороших практических правила выбора скорости обучения из средства поиска скорости обучения?
- Какие два шага выполняет fine_tune метод?
- Как получить исходный код метода или функции в Jupyter Notebook?
- Каковы отличия в скорости обучения?
- Как slice объект Python интерпретируется при передаче fastai в качестве скорости обучения?
- Почему ранняя остановка - плохой выбор при использовании тренировки в один цикл?
- В чем разница между resnet50 и resnet101?
- Что делаетto_fp16?
Дальнейшие исследования
- Найдите статью Лесли Смит, в которой рассказывается о системе определения скорости обучения, и прочтите ее.
- Посмотрите, сможете ли вы повысить точность классификатора в этой главе. Какую максимальную точность вы можете достичь? Посмотрите форумы и веб-сайт книги, чтобы узнать, чего достигли другие студенты с этим набором данных, и как они это сделали.
Метки


Раскрыть комментарии 0
Чтобы оставить комментарий , Вам необходимо Авторизоваться или пройти Регистрацию