
Этика данных
Боковая панель: Благодарность: доктор Рэйчел Томас
Соавтором этой главы является доктор Рэйчел Томас, соучредитель fast.ai и директор-основатель Центра прикладной этики данных Университета Сан-Франциско. Он во многом соответствует части программы, разработанной ею для курса « Введение в этику данных» .
Конечная боковая панель (End sidebar)
Как мы обсуждали в главах 1 и 2, иногда модели машинного обучения могут давать сбой. У них могут быть ошибки. Им можно предоставить данные, которых они раньше не видели, и вести себя так, как мы не ожидаем. Или они могут работать в точности так, как задумано, но использоваться для чего-то, для чего мы бы предпочли, чтобы они никогда не использовались.
Поскольку глубокое обучение является таким мощным инструментом и может использоваться для очень многих вещей, становится особенно важно учитывать последствия нашего выбора. Философское изучение этики - это изучение правильного и неправильного, включая то, как мы можем определить эти термины, распознать правильные и неправильные действия и понять связь между действиями и последствиями. Область этики данных была вокруг в течение долгого времени, и есть много ученых сосредоточены на этой области. Он используется для определения политики во многих юрисдикциях; он используется в больших и малых компаниях, чтобы решить, как лучше всего обеспечить хорошие социальные результаты от разработки продукта; и его используют исследователи, которые хотят убедиться, что выполняемая ими работа используется во благо, а не во вред.
Следовательно, как специалист в области глубокого обучения, вполне вероятно, что в какой-то момент вы попадете в ситуацию, когда вам придется учитывать этику данных. Так что же такое этика данных? Это подполе этики, так что начнем с нее.
Дж .: В университете философия этики была моим главным делом (это была бы тема моей диссертации, если бы я ее закончил, вместо того, чтобы бросить учебу, чтобы присоединиться к реальному миру). Основываясь на годах, которые я потратил на изучение этики, я могу сказать вам следующее: никто на самом деле не согласен с тем, что такое добро и зло, существуют ли они, как их определить, какие люди хорошие, а какие плохие, или что-то еще. Так что не ждите слишком многого от теории! Мы собираемся сосредоточиться здесь на примерах и источниках мысли, а не на теории.
Отвечая на вопрос «Что такое этика» , Центр прикладной этики Марккула говорит, что этот термин относится к: - Обоснованные стандарты добра и зла, предписывающие, что люди должны делать - Изучение и развитие своих этических норм.
Нет списка правильных ответов. Нет никакого списка того, что делать и чего нельзя. Этика сложна и зависит от контекста. Он включает в себя точки зрения многих заинтересованных сторон. Этика - это мускул, который нужно развивать и практиковать. В этой главе наша цель - указать несколько указателей, которые помогут вам в этом путешествии.
Выявление этических проблем лучше всего делать в рамках совместной команды. Это единственный способ действительно включить разные точки зрения. Биография разных людей поможет им увидеть вещи, которые могут быть для вас не очевидны. Работа в команде помогает во многих упражнениях по наращиванию мышц, в том числе и в этом.
Эта глава, конечно, не единственная часть книги, в которой мы говорим об этике данных, но хорошо иметь место, где мы на время сосредоточимся на ней. Чтобы сориентироваться, возможно, проще всего взглянуть на несколько примеров. Итак, мы выбрали три, которые, по нашему мнению, эффективно иллюстрируют некоторые из ключевых тем.
Ключевые примеры этики данных
Мы начнем с трех конкретных примеров, которые иллюстрируют три распространенных этических проблемы в сфере технологий: 1. Процессы обращения за помощью - ошибочные алгоритмы здравоохранения Арканзаса оставляли пациентов в затруднительном положении. 2. Циклы обратной связи. Система рекомендаций YouTube помогла развязать бум теории заговора. 3. Предвзятость. Когда в Google ищут традиционно афроамериканское имя, отображается реклама для проверки на наличие судимости.
Фактически, для каждой концепции, которую мы представляем в этой главе, мы собираемся предоставить хотя бы один конкретный пример. Для каждого подумайте о том, что вы могли бы сделать в этой ситуации, и какие препятствия могли бы вам помешать в этом. Как бы вы с ними справились? На что бы вы обратились?
Ошибки и обращение: алгоритм с ошибками, используемый в целях здравоохранения
The Verge исследовала программное обеспечение, используемое более чем в половине штатов США, чтобы определить, сколько получают люди в сфере здравоохранения, и задокументировала свои выводы в статье «Что происходит, когда алгоритм сокращает ваше здоровье». После внедрения алгоритма в Арканзасе у сотен людей (многие с тяжелыми формами инвалидности) резко сократилось медицинское обслуживание. Например, Тэмми Доббс, женщине с церебральным параличом, которая нуждается в помощи, чтобы помочь ей встать с постели, сходить в туалет, получить еду и многое другое, внезапно сократила часы помощи на 20 часов в неделю. Она не могла получить никаких объяснений, почему ее медицинское обслуживание было сокращено. В конце концов, в судебном процессе выяснилось, что в программной реализации алгоритма были допущены ошибки, что отрицательно сказалось на людях с диабетом или церебральным параличом. Однако Доббс и многие другие люди, полагающиеся на эти медицинские льготы, живут в страхе, что их льготы снова могут быть внезапно и необъяснимо сокращены.
Циклы обратной связи: система рекомендаций YouTube
Циклы обратной связи могут возникать, когда ваша модель управляет следующим циклом получаемых вами данных. Быстро возвращаемые данные искажаются самим программным обеспечением.
Например, у YouTube 1,9 миллиарда пользователей, которые смотрят более 1 миллиарда часов видео на YouTube в день. Его рекомендательный алгоритм (разработанный Google), который был разработан для оптимизации времени просмотра, отвечает примерно за 70% просматриваемого контента. Но возникла проблема: это привело к неконтролируемым циклам обратной связи, в результате чего New York Times опубликовала заголовок «YouTube развязал бум теории заговора. Можно ли его сдержать?» . Якобы системы рекомендаций предсказывают, какой контент понравится людям, но они также обладают большой властью в определении того, какой контент люди вообще видят.
Предвзятость: профессор Латанья Суини "арестован"
Доктор Латанья Суини - профессор Гарвардского университета и директор университетской лаборатории конфиденциальности данных. В статье «Дискриминация при размещении рекламы в Интернете» Она описывает свое открытие, что поиск ее имени в Google привел к появлению рекламных объявлений с надписью «Латаня Суини арестована? хотя она единственная известная Латанья Суини и никогда не подвергалась аресту. Однако при поиске в Google других имен, таких как «Кирстен Линдквист», она получила более нейтральные объявления, хотя Кирстен Линдквист арестовывалась трижды.
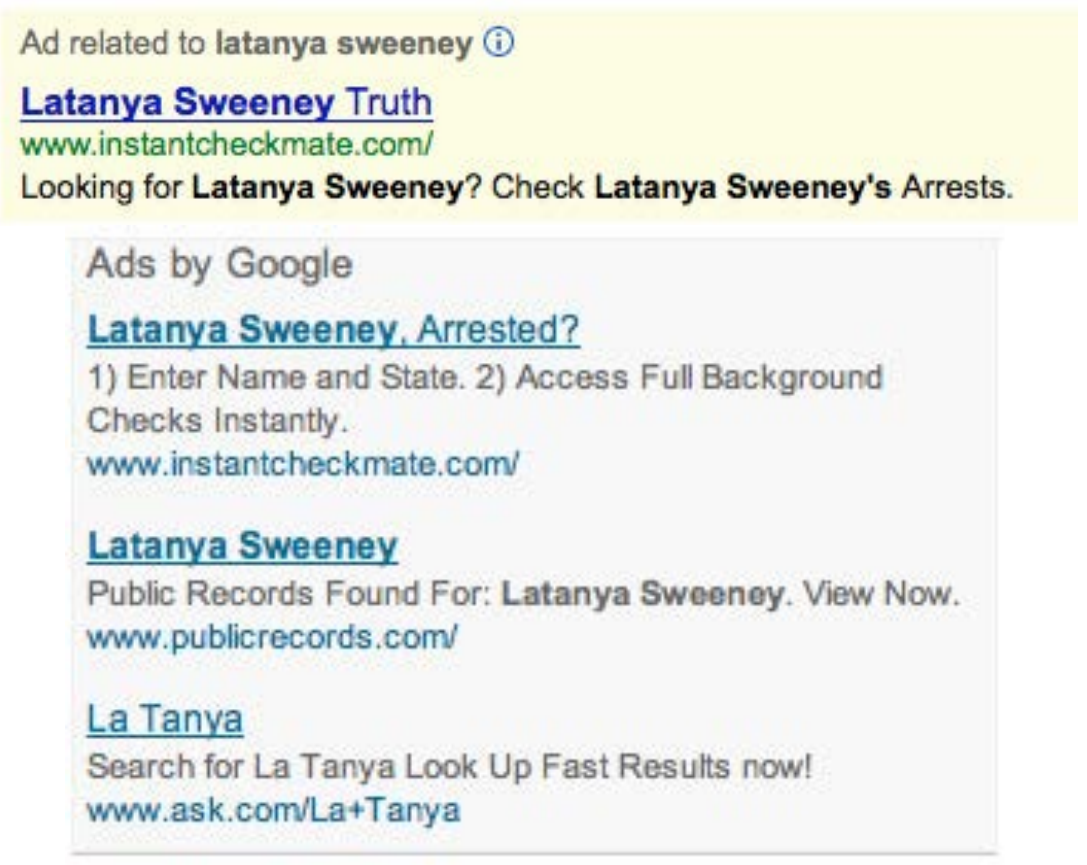
Будучи специалистом по информатике, она изучала это систематически и просмотрела более 2000 имен. Она обнаружила четкую закономерность, когда исторически черные имена получали рекламу, предполагающую, что у человека есть судимость, тогда как белые имена имели более нейтральную рекламу.
Это пример предвзятости. Это может иметь большое значение для жизни людей - например, если соискатель работает в Google, может показаться, что у него есть судимость, а на самом деле это не так.
Почему это важно?
Одна очень естественная реакция на рассмотрение этих вопросов: «И что? Какое это имеет отношение ко мне? Я специалист по данным, а не политик. Я не один из руководителей высшего звена в моей компании, которые принимают решения о что мы делаем. Я просто пытаюсь построить максимально предсказуемую модель, которую я могу ».
Это очень разумные вопросы. Но мы попытаемся убедить вас в том, что ответ заключается в том, что каждому, кто занимается обучением моделей, абсолютно необходимо подумать о том, как их модели будут использоваться, и подумать, как наилучшим образом обеспечить их максимально эффективное использование. Ты можешь кое-что сделать. А если их не делать, то дела могут пойти очень плохо.
Один особенно ужасный пример того, что происходит, когда технологи любой ценой сосредотачиваются на технологиях, - это история IBM и нацистской Германии. В 2001 году швейцарский судья постановил, что было небезосновательно "сделать вывод о том, что техническая помощь IBM облегчила нацистам задачи в совершении их преступлений против человечности, а также действий, связанных с бухгалтерией и классификацией на машинах IBM и использовавшейся в самих концентрационных лагерях. . "
Понимаете, IBM предоставила нацистам продукты для сбора данных, необходимые для отслеживания массового уничтожения евреев и других групп. Это было продвинуто с самого верха компании, с маркетингом для Гитлера и его руководящей команды. Президент компании Томас Уотсон лично одобрил выпуск в 1939 году специальных машин для алфавитного ввода IBM, которые помогут организовать депортацию польских евреев. На снимке < > показана встреча Адольфа Гитлера (крайний слева) с генеральным директором IBM Томом Уотсоном-старшим (второй слева) незадолго до того, как Гитлер наградил Ватсона специальной медалью «За заслуги перед Рейхом» в 1937 году.

Но это не был единичный инцидент - участие организации было обширным. IBM и ее дочерние компании обеспечивали регулярное обучение и техническое обслуживание на месте в концентрационных лагерях: распечатывали карточки, настраивали машины и ремонтировали их, поскольку они часто ломались. IBM установила категоризацию в своей системе перфокарт для того, как был убит каждый человек, к какой группе он был отнесен, а также логистическую информацию, необходимую для отслеживания их через обширную систему Холокоста. Код IBM для евреев в концентрационных лагерях был 8: около 6 миллионов были убиты. Его код для ромов был 12 (нацисты заклеймили их как «асоциальных», при этом более 300 000 человек были убиты в Zigeunerlager , или «цыганском лагере»). Общие казни были закодированы как 4, смерть в газовых камерах как 6.

Конечно, менеджеры проектов, инженеры и техники просто жили своей обычной жизнью. Заботиться о своих семьях, ходить в церковь по воскресеньям, делать свою работу как можно лучше. Следуя приказам. Маркетологи просто делали все возможное для достижения целей развития своего бизнеса. Как заметил Эдвин Блэк, автор книги IBM and the Holocaust (Dialog Press): «Для слепого технократа средства были важнее, чем цели. Уничтожение еврейского народа стало еще менее важным, потому что воодушевляющая природа технических достижений IBM была только усиление фантастической прибыли, которую можно получить в то время, когда очереди за хлебом тянулись по всему миру ».
Вернитесь на мгновение назад и подумайте: что бы вы почувствовали, если бы обнаружили, что были частью системы, которая в конечном итоге нанесла вред обществу? Вы были бы готовы узнать? Как вы можете сделать так, чтобы этого не произошло? Мы описали здесь наиболее экстремальную ситуацию, но сегодня наблюдается множество негативных социальных последствий, связанных с ИИ и машинным обучением, некоторые из которых мы опишем в этой главе.
И это не просто моральное бремя. Иногда технологи напрямую платят за свои действия. Например, первым человеком, попавшим в тюрьму в результате скандала с Volkswagen, когда выяснилось, что автомобильная компания обманула тесты на выбросы дизельных двигателей, не был менеджер, курировавший проект, или руководитель компании. . Это был один из инженеров, Джеймс Лян, который просто сделал то, что ему сказали.
Конечно, не все так плохо - если проект, в котором вы участвуете, окажет огромное положительное влияние хотя бы на одного человека, вы почувствуете себя прекрасно!
Хорошо, надеюсь, мы убедили вас в том, что вам следует позаботиться. Но что делать? Как специалисты по обработке данных, мы, естественно, склонны сосредоточиться на улучшении наших моделей за счет оптимизации тех или иных показателей. Но оптимизация этого показателя на самом деле может не привести к лучшим результатам. И даже если это действительно поможет добиться лучших результатов, это почти наверняка не единственное, что имеет значение. Рассмотрим последовательность шагов, которая происходит между разработкой модели или алгоритма исследователем или практиком, и точкой, в которой эта работа фактически используется для принятия того или иного решения. Весь этот конвейер необходимо рассматривать как единое целое, если мы хотим иметь надежду на получение желаемых результатов.
Обычно от одного конца до другого идет очень длинная цепочка. Это особенно верно, если вы исследователь, и вы можете даже не знать, пригодятся ли ваши исследования для чего-либо, или если вы участвуете в сборе данных, который еще раньше находится в стадии разработки. Но никто не может лучше информировать всех участников этой цепочки о возможностях, ограничениях и деталях вашей работы, чем вы. Хотя не существует «серебряной пули», которая могла бы гарантировать правильное использование вашей работы, участвуя в процессе и задавая правильные вопросы, вы можете, по крайней мере, обеспечить рассмотрение правильных вопросов.
Иногда правильный ответ на просьбу о работе - просто сказать «нет». Однако часто мы слышим ответ: «Если я этого не сделаю, это сделает кто-то другой». Но учтите следующее: если вас выбрали для работы, вы лучший человек, которого они нашли для этого, поэтому, если вы этого не сделаете, лучший человек не будет работать над этим проектом. Даже лучше, если первые пять человек, которых они спрашивают, тоже откажутся!
Интеграция машинного обучения с дизайном продукта
По-видимому, вы делаете эту работу потому, что надеетесь, что она будет для чего-то использована. В противном случае вы просто зря теряете время. Итак, начнем с предположения, что ваша работа где-то закончится. Теперь, когда вы собираете данные и разрабатываете модель, вы принимаете множество решений. На каком уровне агрегирования вы будете хранить свои данные? Какую функцию потерь следует использовать? Какие наборы для проверки и обучения следует использовать? Следует ли сосредоточиться на простоте реализации, скорости вывода или точности модели? Как ваша модель будет обрабатывать элементы данных вне домена? Можно ли его настроить или со временем нужно переобучать с нуля?
Это не просто вопросы алгоритма. Это вопросы проектирования информационных продуктов. Но менеджеры по продукту, руководители, судьи, журналисты, врачи… все, кто в конечном итоге разработает и использует систему, частью которой является ваша модель, не будут иметь возможности понимать принятые вами решения, не говоря уже об их изменении.
Например, два исследования показали, что программное обеспечение для распознавания лиц Amazon дает неточные и расовые результаты. Amazon заявила, что исследователям следовало изменить параметры по умолчанию, не объясняя, как это могло бы изменить предвзятые результаты. Более того, выяснилось, что Amazon не инструктировал полицейские управления который также использовал для этого свое программное обеспечение. Предположительно, существовала большая дистанция между исследователями, разработавшими эти алгоритмы, и сотрудниками отдела документации Amazon, которые написали инструкции, предоставляемые полиции. Отсутствие тесной интеграции привело к серьезным проблемам для общества в целом, полиции и самих Amazon. Оказалось, что их система ошибочно сопоставила 28 членов Конгресса с криминальными фотографиями! (И конгрессмены, ошибочно сопоставленные с криминальными фотографиями, были непропорционально цветными людьми, как видно из < >.)

Специалисты по анализу данных должны быть частью междисциплинарной команды. И исследователям необходимо тесно сотрудничать с людьми, которые в конечном итоге будут использовать их исследования. Еще лучше, если бы сами эксперты в предметной области узнали достаточно, чтобы иметь возможность самостоятельно обучать и отлаживать некоторые модели - надеюсь, некоторые из вас читают эту книгу прямо сейчас!
Современное рабочее место - очень специализированное место. Каждый стремится выполнять четко определенную работу. Особенно в крупных компаниях бывает сложно понять, из чего состоит головоломка. Иногда компании даже намеренно скрывают общие цели проекта, над которыми они работают, если знают, что их сотрудникам не понравятся ответы. Иногда это делается путем максимально возможного разделения частей.
Другими словами, мы не говорим, что все это легко. Это тяжело. Это действительно трудно. Мы все должны делать все возможное. И мы часто видели, что люди, которые участвуют в контексте этих проектов более высокого уровня и пытаются развивать междисциплинарные способности и команды, становятся одними из самых важных и хорошо вознагражденных членов своих организаций. Это тот вид работы, который обычно высоко ценится руководителями высшего звена, даже если руководство среднего звена иногда считает ее довольно неудобной.
Темы этики данных
Этика данных - это большая область, и мы не можем охватить все. Вместо этого мы собираемся выбрать несколько тем, которые, по нашему мнению, особенно актуальны: - Потребность в обращении за помощью и подотчетности - Петли обратной связи - Предвзятость - Дезинформация
Давайте рассмотрим каждый по очереди.
Средства правовой защиты и подотчетность
В сложной системе никто не чувствует ответственности за результаты. Хотя это и понятно, к хорошим результатам это не приводит. В предыдущем примере системы здравоохранения Арканзаса, в которой ошибка привела к тому, что люди с церебральным параличом потеряли доступ к необходимой помощи, создатель алгоритма обвинил правительственных чиновников, а правительственные чиновники - тех, кто внедрил программное обеспечение. Профессор Нью-Йоркского университета Дана Бойд описал этот феномен: «Бюрократия часто использовалась, чтобы переложить ответственность или избежать ответственности ... Сегодняшние алгоритмические системы расширяют бюрократию».
Еще одна причина, по которой обращение за помощью так необходимо, заключается в том, что данные часто содержат ошибки. Решающее значение имеют механизмы аудита и исправления ошибок. База данных предполагаемых членов банды, которую ведут сотрудники правоохранительных органов Калифорнии, оказалась полна ошибок, в том числе 42 младенцев, которые были добавлены в базу данных, когда им было меньше 1 года (28 из которых были отмечены как «признающие себя в банде»). члены »). В данном случае не было процесса исправления ошибок или удаления людей после того, как они были добавлены. Другой пример - система кредитных отчетов в США: в ходе масштабного исследования кредитных отчетов Федеральной торговой комиссией (FTC) в 2012 году было обнаружено, что 26% потребителей имели хотя бы одну ошибку в своих файлах, а 5% - ошибки, которые могут быть разрушительными. Пока что, процесс исправления таких ошибок невероятно медленный и непрозрачный. Когда репортер общественного радио Бобби Аллин обнаружил, что он был ошибочно внесен в список как имеющий судимость за огнестрельное оружие, ему потребовалось «более десятка телефонных звонков, работа клерка окружного суда и шесть недель, чтобы решить проблему. И это было только после того, как я связался с отделом связи компании. отдел как журналист ".
Как практикующие машинное обучение, мы не всегда считаем своей обязанностью понять, как наши алгоритмы в конечном итоге реализуются на практике. Но нам нужно.
Обратная связь
Мы объяснили в < >, как алгоритм может взаимодействовать со своей средой для создания цикла обратной связи, делая прогнозы, которые подкрепляют действия, предпринимаемые в реальном мире, что приводит к еще более выраженным прогнозам в том же направлении. В качестве примера снова рассмотрим систему рекомендаций YouTube. Пару лет назад команда Google рассказывала о том, как они внедрили обучение с подкреплением (тесно связанное с глубоким обучением, но где ваша функция потерь представляет результат, возможно, спустя долгое время после того, как произошло действие), чтобы улучшить систему рекомендаций YouTube. Они описали, как использовали алгоритм, который давал рекомендации по оптимизации времени просмотра.
Однако людей обычно привлекает спорный контент. Это означало, что видео о таких вещах, как теории заговора, начали все чаще и чаще рекомендовать система рекомендаций. Более того, оказывается, что теориями заговора интересуются люди, которые смотрят много онлайн-видео! Итак, их все больше и больше привлекает YouTube. Увеличение числа сторонников теории заговора, просматривающих видео на YouTube, привело к тому, что алгоритм рекомендовал все больше и больше теорий заговора и другого экстремистского контента, что привело к тому, что все больше экстремистов смотрели видео на YouTube, а все больше людей смотрели YouTube, развивая экстремистские взгляды, что привело к тому, что алгоритм рекомендовал больше экстремистского содержания ... Система выходила из-под контроля.
И это явление не ограничивалось этим конкретным типом контента. В июне 2019 года New York Times опубликовала статью о системе рекомендаций YouTube под названием «На цифровой игровой площадке YouTube, открытыми воротами для педофилов» . Статья началась с пугающей истории:
: Christiane C. ничего об этом не подумала, когда ее 10-летняя дочь и друг загрузили видео, на котором они играют в бассейне на заднем дворе… Несколько дней спустя… у видео были тысячи просмотров. Вскоре оно выросло до 400 000 ... «Я снова посмотрела видео и испугалась количества просмотров», - сказала Кристиана. У нее была причина. Автоматизированная система рекомендаций YouTube ... начала показывать видео пользователям, которые смотрели другие видео с участием детей в препубертатном возрасте, частично одетых, как выяснила группа исследователей.
: Само по себе каждое видео может быть совершенно невинным, скажем, домашним фильмом, снятым ребенком. Любые раскрывающиеся кадры мимолетны и кажутся случайными. Но, сгруппированные вместе, их общие черты становятся безошибочными.
Алгоритм рекомендаций YouTube начал подбирать плейлисты для педофилов, отбирая невинные домашние видео, в которых оказались несовершеннолетние, частично одетые дети.
Никто в Google не планируется создать систему, которая превратила семейное видео в порно для педофилов. Итак, что случилось?
Отчасти проблема здесь в том, что метрики играют центральную роль в управлении финансово важной системой. Когда у алгоритма есть метрика для оптимизации, как вы видели, он сделает все возможное, чтобы оптимизировать это число. Это имеет тенденцию приводить ко всем видам крайних случаев, и люди, взаимодействующие с системой, будут искать, находить и использовать эти крайние случаи и петли обратной связи в своих интересах.
Есть признаки того, что именно это и произошло с системой рекомендаций YouTube. The Guardian опубликовала статью под названием «Как бывший участник программы предварительной оценки YouTube исследовал свой секретный алгоритм» о Гийоме Часло, бывшем инженере YouTube, который создал алгоритм AlgoTransparency, который отслеживает эти проблемы. Часло опубликовал диаграмму в разделе < > после выхода Роберта Мюллера «Отчет о расследовании российского вмешательства в президентские выборы 2016 года».
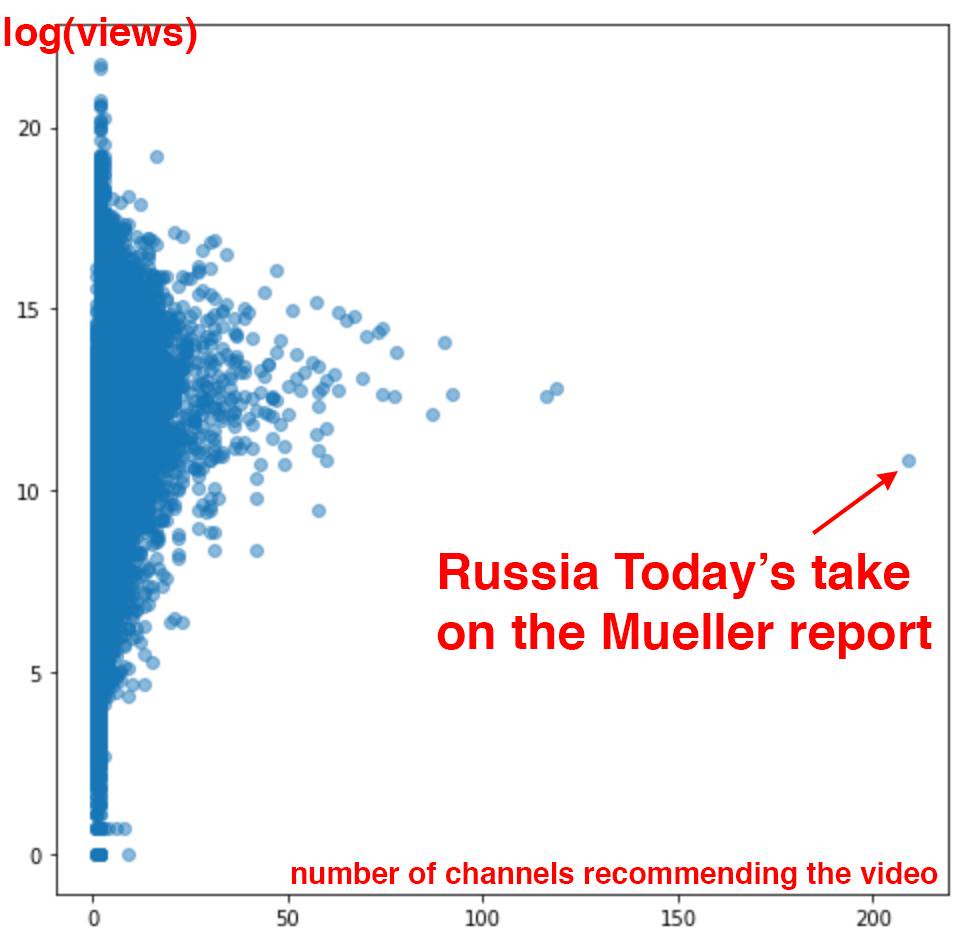
Освещение доклада Мюллера Russia Today было крайне неожиданным с точки зрения того, сколько каналов рекомендовали его. Это предполагает возможность того, что российское государственное информационное агентство Russia Today преуспело в использовании алгоритма рекомендаций YouTube. К сожалению, непрозрачность подобных систем затрудняет выявление проблем, которые мы обсуждаем.
Один из наших рецензентов этой книги, Орелиен Жерон, руководил командой YouTube по классификации видео с 2013 по 2016 год (задолго до событий, обсуждаемых здесь). Он отметил, что проблема заключается не только в петлях обратной связи с участием людей. Без людей тоже могут быть петли обратной связи! Он рассказал нам о примере с YouTube:
: Одним из важных сигналов для классификации основной темы видео является канал, с которого оно исходит. Например, видео, загруженное на кулинарный канал, скорее всего, будет видео о кулинарии. Но как узнать, о какой теме идет канал? Что ж ... частично, глядя на темы содержащихся в нем видео! Вы видите петлю? Например, у многих видеороликов есть описание, в котором указано, какая камера использовалась для съемки видео. В результате некоторые из этих видеороликов могут быть классифицированы как видеоролики о «фотографии». Если на канале есть такое неверно классифицированное видео, его можно классифицировать как «фотографический», что еще более повышает вероятность того, что будущие видео на этом канале будут ошибочно классифицированы как «фотографические». Это может даже привести к неконтролируемым вирусным классификациям! Один из способов разорвать эту петлю обратной связи - классифицировать видео с сигналом канала и без него. Тогда при классификации каналов вы можете использовать только классы, полученные без сигнала канала. Таким образом, цикл обратной связи нарушается.
Есть положительные примеры людей и организаций, пытающихся бороться с этими проблемами. Эван Эстола, ведущий инженер по машинному обучению Meetup, рассказал об этом примере.мужчин, которые проявляют больший интерес к техническим встречам, чем женщины. Таким образом, учет пола может привести к тому, что алгоритм Meetup будет рекомендовать женщинам меньше технических встреч, и в результате меньшее количество женщин будет узнавать о технических встречах и посещать их, что может привести к тому, что алгоритм будет предлагать женщинам еще меньше технических встреч и т. д. в самоусиливающейся петле обратной связи. Итак, Эван и его команда приняли этическое решение для своего алгоритма рекомендаций не создавать такую петлю обратной связи, явно не используя гендер для этой части своей модели. Отрадно видеть, что компания не просто бездумно оптимизирует метрику, но учитывает ее влияние. По словам Эвана, «вам нужно решить, какую функцию не использовать в вашем алгоритме ... самый оптимальный алгоритм, возможно, не лучший для запуска в производство».
В то время как Meetup предпочла избежать такого исхода, Facebook дает пример того, как разгуляться неконтролируемой петле обратной связи. Как и YouTube, он имеет тенденцию радикализировать пользователей, заинтересованных в одной теории заговора, знакомя их с другими. Как Рене DiResta, исследователь по распространению дезинформации, пишет :
: Как только люди присоединяются к единой группе [Facebook], ориентированной на заговор, они алгоритмически перенаправляются к множеству других. Присоединяйтесь к группе противников вакцины, и ваши предложения будут включать в себя анти-ГМО, часы с химическим следом, плоскую Землю (да, действительно) и «естественное лечение рака. Вместо того, чтобы вытаскивать пользователя из кроличьей норы, механизм рекомендаций подталкивает их. дальше в. "
Чрезвычайно важно помнить, что такое поведение может происходить, и либо предвидеть петлю обратной связи, либо принимать позитивные меры, чтобы ее разорвать, когда вы видите первые признаки этого в своих собственных проектах. Еще одна вещь, о которой следует помнить, - это предвзятость , которая, как мы вкратце обсуждали в предыдущей главе, может очень неприятно взаимодействовать с петлями обратной связи.
Предвзятость
Обсуждения предвзятости в Интернете, как правило, довольно быстро запутываются. Слово «предвзятость» означает очень много разных вещей. Когда специалисты по этике данных говорят о предвзятости, статистики часто думают, что они имеют в виду статистическое определение термина "предвзятость". Но это не так. И они уж точно не говорят о смещениях, которые проявляются в весах и смещениях, которые являются параметрами вашей модели!
Речь идет о концепции предвзятости в социальных науках. В статье «Основы для понимания непредвиденных последствий машинного обучения» Харини Суреш и Джон Гуттаг из Массачусетского технологического института описывают шесть типов предвзятости в машинном обучении, кратко изложенных в < > из их статьи.

Мы обсудим четыре из этих типов предвзятости, те, которые мы сочли наиболее полезными в нашей собственной работе (подробности о других см. В статье).
Исторический уклон
Историческая предвзятость возникает из-за предвзятости людей, предвзятости процессов и предвзятости общества. Суреш и Гуттаг говорят: «Историческая предвзятость является фундаментальной структурной проблемой на первом этапе процесса генерации данных и может существовать даже при идеальной выборке и выборе признаков».
Например, вот несколько примеров исторического смещения гонки в США, из Нью - Йорк Таймс статьи «расовый предрассудок, даже когда у нас есть хорошие намерения» по Университету Чикаго Сендхил Mullainathan:
- Когда докторам показывали идентичные файлы, они с гораздо меньшей вероятностью рекомендовали катетеризацию сердца (полезная процедура) чернокожим пациентам.
- При торгах за подержанный автомобиль чернокожим предлагали начальную цену на 700 долларов выше и получали гораздо меньшие уступки.
- Ответы на объявления об аренде квартир на Craigslist с черным именем вызвали меньше откликов, чем с белым именем.
- Присяжные, состоящие исключительно из белых, на 16 процентных пунктов чаще выносили обвинительный приговор черному обвиняемому, чем белому, но когда в присяжных входил один черный член, оно выносило приговор обоим с одинаковой скоростью.
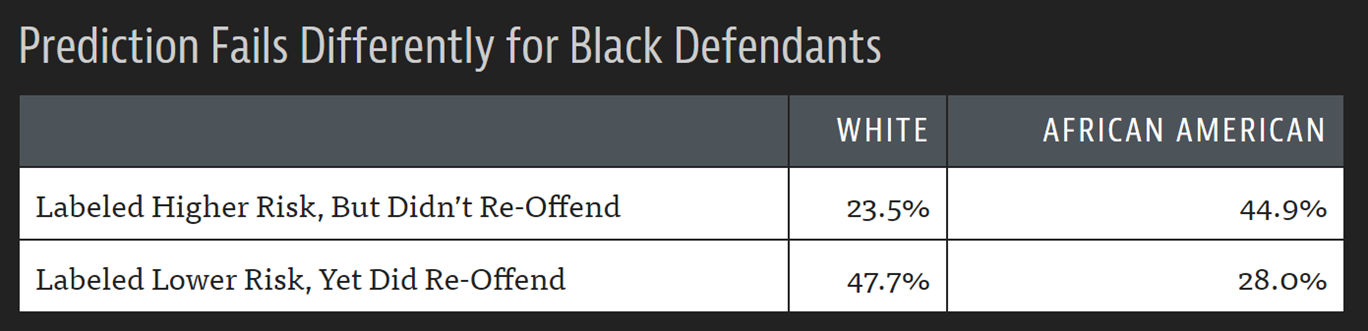
Алгоритм COMPAS, широко используемый для вынесения приговора и решений об освобождении под залог в США, является примером важного алгоритма, который при тестировании ProPublica на практике показал явную расовую предвзятость (< >).
Любой набор данных с участием людей может иметь такую предвзятость: медицинские данные, данные о продажах, данные о жилье, политические данные и так далее. Поскольку основная предвзятость настолько распространена, предвзятость в наборах данных очень распространена. Расовая предвзятость проявляется даже в компьютерном зрении, как показано на примере фотографий с автоматической категоризацией, опубликованных в Twitter пользователем Google Фото, показанных в < >.
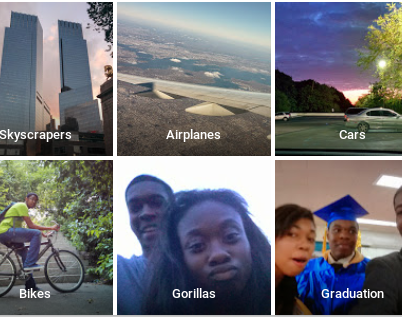
Да, это показывает то, что вы думаете: Google Фото классифицировал фотографию темнокожего пользователя с его другом как «гориллы»! Эта алгоритмическая оплошность привлекла большое внимание средств массовой информации. «Мы потрясены и искренне сожалеем о том, что это произошло», - заявила представитель компании. «Очевидно, что еще предстоит проделать большую работу с автоматической маркировкой изображений, и мы ищем способы предотвратить подобные ошибки в будущем».
К сожалению, исправить проблемы в системах машинного обучения, когда есть проблемы с входными данными, сложно. Первая попытка Google не вызвала доверия, как предполагало издание The Guardian (< >).

Подобные проблемы, конечно же, не ограничиваются только Google. Исследователи Массачусетского технологического института изучили самые популярные онлайн-API компьютерного зрения, чтобы убедиться, насколько они точны. Но они не просто вычислили одно число точности - вместо этого они посмотрели на точность в четырех разных группах, как показано в < >.
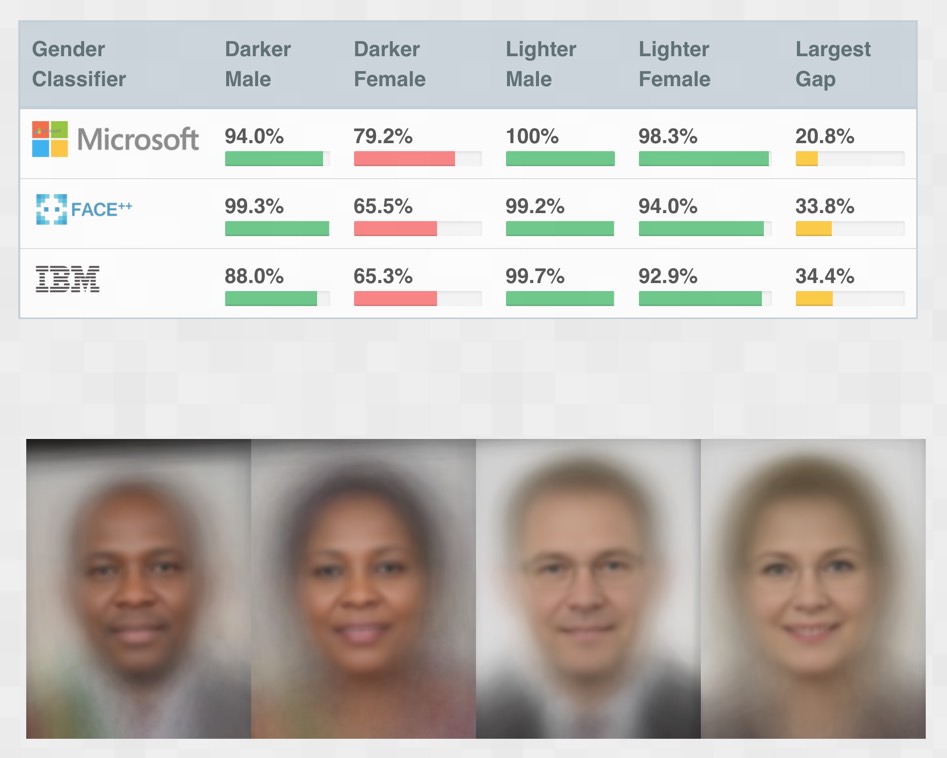
Система IBM, например, имела коэффициент ошибок 34,7% для темных женщин по сравнению с 0,3% для более светлых мужчин - в 100 раз больше ошибок! Некоторые люди неправильно отреагировали на эти эксперименты, заявив, что разница заключалась просто в том, что более темная кожа сложнее распознавать компьютерами. Однако на самом деле произошло то, что после негативной огласки, вызванной этим результатом, все рассматриваемые компании резко улучшили свои модели для более темной кожи, так что год спустя они были почти так же хороши, как и для более светлой кожи. Фактически это показало, что разработчики не смогли использовать наборы данных, содержащие достаточно темных лиц, или протестировать свой продукт с более темными лицами.
Один из исследователей Массачусетского технологического института, Джой Буоламвини, предупредил: «Мы вступили в эпоху автоматизации, будучи чрезмерно самоуверенными, но недостаточно подготовленными. Если мы не сможем создать этичный и всеобъемлющий искусственный интеллект, мы рискуем потерять успехи, достигнутые в области гражданских прав и гендерного равенства под видом машины. нейтралитет ".
Частично проблема заключается в систематическом дисбалансе в составе популярных наборов данных, используемых для обучения моделей. Аннотация к статье Шреи Шанкара и др. «Нет классификации без представления: оценка вопросов георазнообразия в наборах открытых данных для развивающихся стран» . заявляет: «Мы анализируем два больших общедоступных набора данных изображений для оценки географического разнообразия и обнаруживаем, что эти наборы данных, по-видимому, демонстрируют наблюдаемую предвзятость амероцентрического и евроцентрического представления. Кроме того, мы анализируем классификаторы, обученные этим наборам данных, чтобы оценить влияние эти обучающие распределения и обнаруживают сильные различия в относительной производительности на изображениях из разных регионов ». <> показывает одну из диаграмм из статьи, показывающую географический состав двух наиболее важных наборов данных изображений для обучения моделей в то время (и остается, пока пишется эта книга).
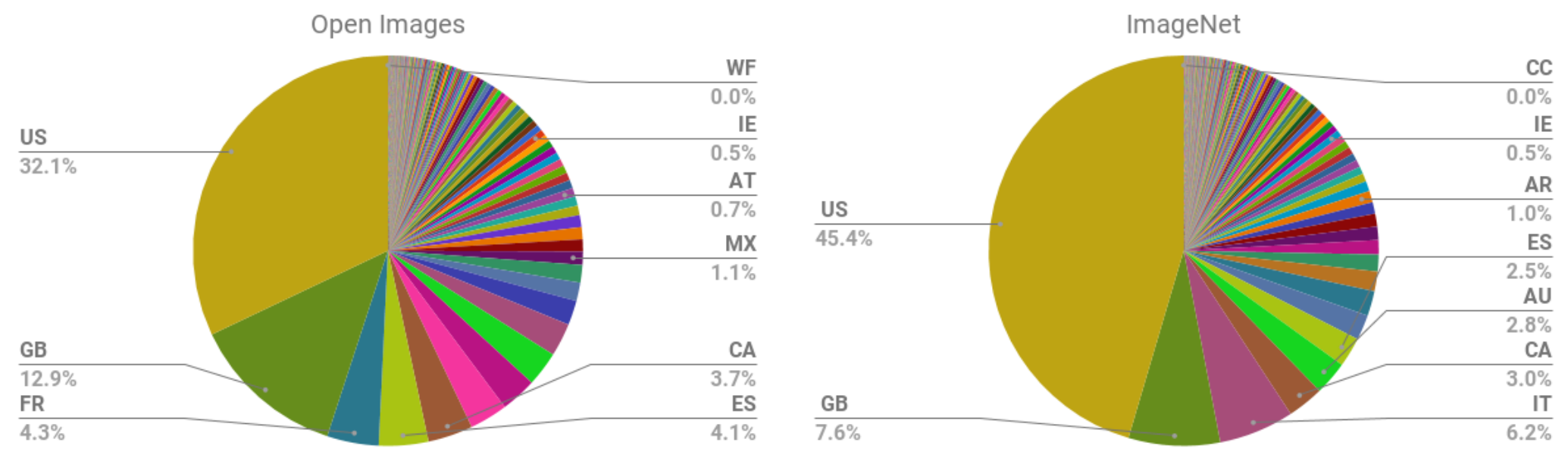
Подавляющее большинство изображений сделано из США и других западных стран, поэтому модели, обученные в ImageNet, хуже работают со сценами из других стран и культур. Например, исследование показало, что такие модели хуже идентифицируют предметы домашнего обихода (например, мыло, специи, диваны или кровати) из стран с низкими доходами. < > показывает изображение из статьи "Работает ли распознавание объектов для всех?" Терранс Де Вриз и др. исследования Facebook AI Research, который иллюстрирует эту точку зрения.

В этом примере мы видим, что пример мыла с низкими доходами очень далек от точности, поскольку каждая коммерческая служба распознавания изображений предсказывает «еда» как наиболее вероятный ответ!
Как мы вскоре обсудим, подавляющее большинство исследователей и разработчиков ИИ - молодые белые мужчины. Большинство проектов, которые мы видели, в большинстве случаев тестируются пользователями с участием друзей и родственников, непосредственно занимающихся разработкой продукта. Учитывая это, проблемы, которые мы только что обсудили, не должны вызывать удивления.
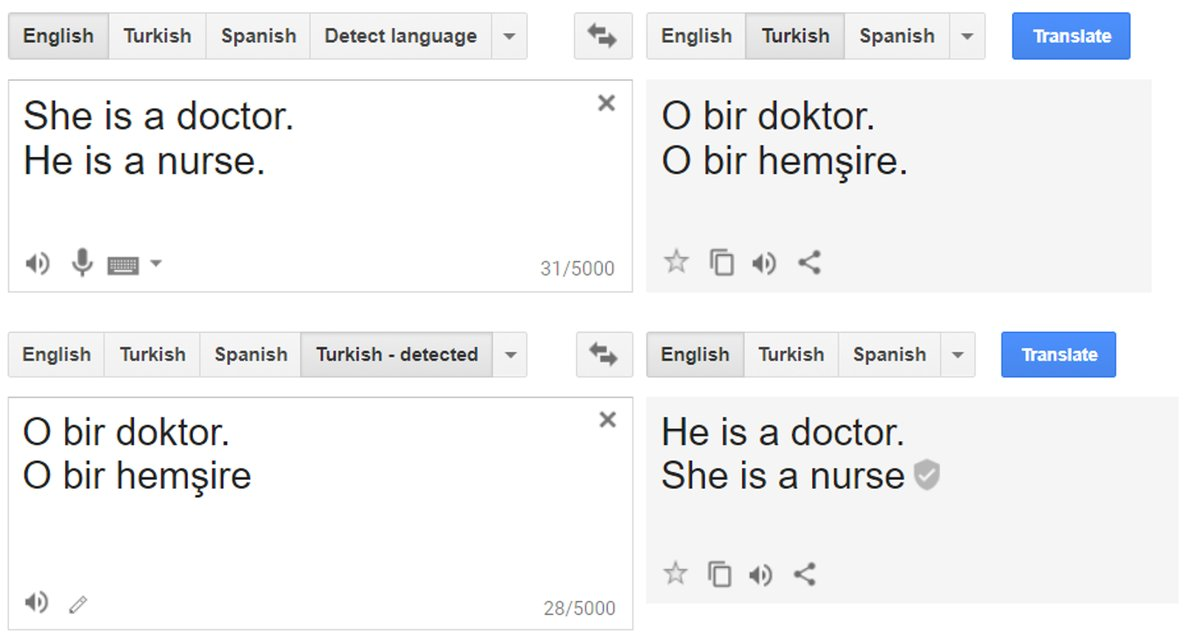
Аналогичная историческая предвзятость обнаруживается в текстах, используемых в качестве данных для моделей обработки естественного языка. Это во многих отношениях возникает в последующих задачах машинного обучения. Например, широко сообщалось, что до прошлого года Google Translate демонстрировал систематическую предвзятость в том, как он переводил турецкое гендерно-нейтральное местоимение «o» на английский язык: применительно к должностям, которые часто связаны с мужчинами, он использовал «он», а когда применительно к профессиям, которые часто связаны с женщинами, используется слово «она» (< >).
Мы также видим такую предвзятость в онлайн-рекламе. Например, исследованиеМухаммеда Али и др. В 2019 году. обнаружили, что даже когда человек, размещающий рекламу, не делает намеренно дискриминационных, Facebook будет показывать рекламу очень разным аудиториям в зависимости от расы и пола. Рекламу жилья с тем же текстом, но с изображением семьи белых или чернокожих, демонстрировали аудитории, различающиеся по расовому признаку.
Ошибка измерения
В статье «Автоматизирует ли машинное обучение моральные опасности и ошибки» в журнале American Economic Review Сендхил Муллайнатан и Зиад Обермейер рассматривают модель, которая пытается ответить на вопрос: с помощью исторических данных электронных медицинских карт (EHR) какие факторы наиболее предсказуемы. Инсульт? Это главные предикторы модели:
- Предыдущий инсульт
- Сердечно-сосудистые заболевания
- Случайная травма
- Доброкачественная опухоль в груди
- Колоноскопия
- Синусит
Однако только две верхние позиции имеют отношение к удару! Основываясь на том, что мы изучили до сих пор, вы, вероятно, можете догадаться, почему. На самом деле мы не измеряли инсульт , который возникает, когда в какой-то области мозга не хватает кислорода из-за нарушения кровоснабжения. Мы измерили, у кого были симптомы, у кого были обращения к врачу, прошли соответствующие анализы и у кого диагностировали инсульт. На самом деле инсульт - это не единственное, что связано с этим полным списком - это также связано с тем, кто действительно идет к врачу (на который влияет то, у кого есть доступ к здравоохранению, может ли он позволить себе доплату, не так ли? не подвергались медицинской дискриминации по признаку расы или пола и т. д.)! Если вы собираетесь обратиться к врачу из-за случайной травмы, то вы, вероятно, также обратитесь к врачу, когда у вас случится инсульт.
Это пример систематической ошибки измерения . Это происходит, когда наши модели делают ошибки из-за того, что мы измеряем не то, или измеряем неправильно, или неправильно включаем это измерение в модель.
Смещение агрегирования
Ошибка агрегирования возникает, когда модели не агрегируют данные таким образом, чтобы включать все соответствующие факторы, или когда модель не включает необходимые условия взаимодействия, нелинейности и т. Д. Это может особенно произойти в медицинских учреждениях. Например, способ лечения диабета часто основан на простой одномерной статистике и исследованиях с участием небольших групп разнородных людей. Анализ результатов часто проводится без учета различий в этнической или гендерной принадлежности. Однако выясняется, что у пациентов с диабетом есть разные осложнения у разных национальностей , а уровни HbA1c (широко используемые для диагностики и мониторинга диабета) сложным образом различаются в зависимости от этнической принадлежности и пола.. Это может привести к неправильному диагнозу или лечению людей, потому что медицинские решения основаны на модели, которая не включает эти важные переменные и взаимодействия.
Предвзятость представления
Конспект бумаги «Bias в Bios: социологическое исследование семантического представления смещения в высокочастотном Stakes Настройки» Мария де-Артеаге и др. отмечает, что существует гендерный дисбаланс в профессиях (например, женщины с большей вероятностью будут медсестрами, а мужчины с большей вероятностью будут пасторами), и говорит, что: «различия в истинно положительных показателях между полами коррелируют с существующим гендерным дисбалансом в профессиях, что может усугубить эти дисбалансы ".
Другими словами, исследователи заметили, что модели, прогнозирующие род занятий, не только отражают фактический гендерный дисбаланс в основной популяции, но и усиливают его! Этот тип предвзятости представления довольно распространен, особенно для простых моделей. Когда существует какая-то ясная, легко видимая основополагающая взаимосвязь, простая модель часто просто предполагает, что эта взаимосвязь сохраняется все время. Как показано в документе < >, для профессий, в которых процент женщин выше, модель имела тенденцию переоценивать распространенность этого занятия.
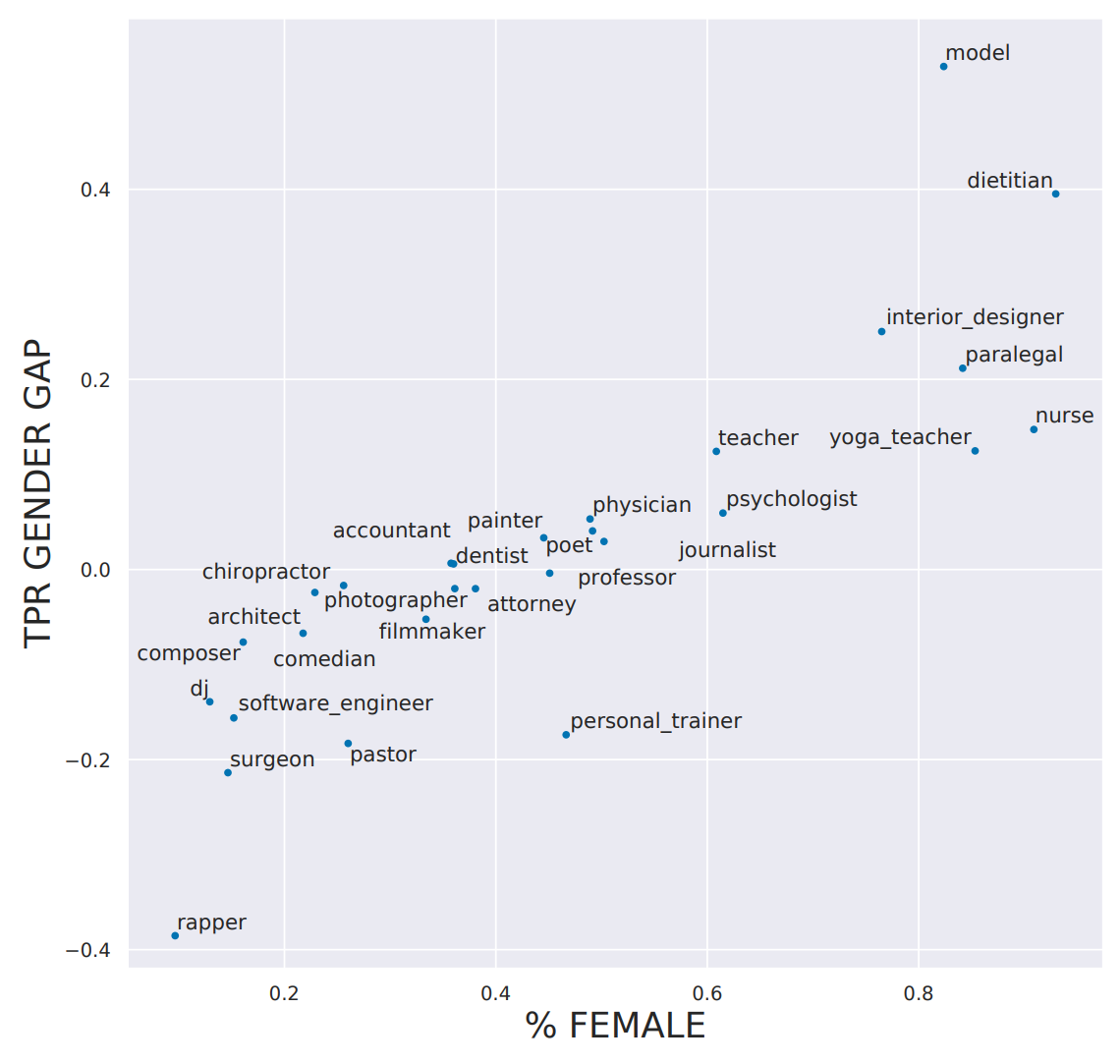
Например, в наборе обучающих данных 14,6% хирургов составляли женщины, а в прогнозах модели только 11,6% истинно положительных результатов были женщинами. Таким образом, модель усиливает смещение, существующее в обучающей выборке.
Теперь, когда мы увидели, что эти предубеждения существуют, что мы можем сделать, чтобы их смягчить?
Устранение различных типов предвзятости
Различные типы предвзятости требуют разных подходов к смягчению. Хотя сбор более разнообразного набора данных может решить проблему систематической ошибки представления, это не поможет устранить историческую ошибку или ошибку измерения. Все наборы данных содержат систематическую ошибку. Нет такой вещи, как полностью измененный набор данных. Многие исследователи в этой области пришли к набору предложений, позволяющих лучше документировать решения, контекст и особенности того, как и почему был создан конкретный набор данных, в каких сценариях он подходит для использования и каковы ограничения. Таким образом, те, кто использует конкретный набор данных, не будут застигнуты врасплох его предубеждениями и ограничениями.
Мы часто слышим вопрос: «Люди предвзяты, имеет ли значение алгоритмическая предвзятость?» Это возникает так часто, что должно быть какое-то рассуждение, которое имеет смысл для людей, которые его задают, но нам это кажется не очень логичным! Независимо от того, является ли это логичным, важно понимать, что алгоритмы (особенно алгоритмы машинного обучения!) И люди разные. Обратите внимание на следующие моменты об алгоритмах машинного обучения:
- Машинное обучение может создавать петли обратной связи : небольшая систематическая ошибка может быстро увеличиваться экспоненциально из-за петель обратной связи.
- Машинное обучение может усилить предвзятость :: предвзятость человека может привести к увеличению предвзятости машинного обучения.
- Алгоритмы и люди используются по-разному : люди, принимающие решения, и лица, принимающие алгоритмические решения, на практике не используются взаимозаменяемым образом по принципу plug-and-play.
- Технология - это сила :: А вместе с ней возникает ответственность.
Как показал пример системы здравоохранения Арканзаса, машинное обучение часто применяется на практике не потому, что оно приводит к лучшим результатам, а потому, что оно дешевле и эффективнее. Кэти О'Нил в своей книге « Оружие разрушения математики» («Корона») описала модель того, как привилегированные обрабатываются людьми, а бедные обрабатываются алгоритмами. Это всего лишь один из множества способов использования алгоритмов иначе, чем людей, принимающих решения. Другие включают:
- Люди с большей вероятностью будут считать алгоритмы объективными или безошибочными (даже если им предоставляется возможность переопределения человеком).
- Алгоритмы с большей вероятностью будут реализованы без процесса обжалования.
- Алгоритмы часто используются масштабно.
- Алгоритмические системы дешевы.
Даже при отсутствии предвзятости алгоритмы (и особенно глубокое обучение, поскольку это такой эффективный и масштабируемый алгоритм) могут привести к негативным социальным проблемам, например, при использовании для дезинформации .
Дезинформация
История дезинформации насчитывает сотни или даже тысячи лет. Речь идет не обязательно о том, чтобы заставить кого-то поверить во что-то ложное, а скорее всего, чтобы посеять дисгармонию и неуверенность и заставить людей отказаться от поиска истины. Получение конфликтующих аккаунтов может заставить людей предположить, что они никогда не узнают, кому и чему доверять.
Некоторые люди думают, что дезинформация - это прежде всего ложная информация или фейковые новости , но в действительности дезинформация часто может содержать семена правды или полуправды, вырванной из контекста. Ладислав Биттман был офицером разведки в СССР, который позже перешел на сторону США и написал несколько книг в 1970-х и 1980-х годах о роли дезинформации в советских пропагандистских операциях. В книге «КГБ и советская дезинформация» (Пергамон) он писал: «Большинство кампаний - это тщательно продуманная смесь фактов, полуправды, преувеличений и преднамеренной лжи».
В США это стало почти очевидным в последние годы, поскольку ФБР подробно описывает масштабную кампанию дезинформации, связанную с Россией на выборах 2016 года. Понимание дезинформации, использованной в этой кампании, очень поучительно. Например, ФБР обнаружило, что российская кампания дезинформации часто организовывала две отдельные поддельные акции массового протеста, по одной для каждой стороны проблемы, и заставляла их протестовать одновременно! Houston Chronicle сообщается на одном из этих нечетных событий (< >).
: Группа, которая назвала себя «Сердце Техаса», организовала его в социальных сетях - они заявили, что протестуют против «исламизации» Техаса. На одной стороне Трэвис-стрит я нашел около 10 протестующих. С другой стороны, я нашел около 50 контрпротестующих. Но мне не удалось найти организаторов митинга. Никакого «сердца Техаса». Я подумал, что это странно, и упомянул об этом в статье: «Какая группа не участвует в своем мероприятии? Теперь я знаю почему. Судя по всему, в то время организаторы митинга находились в Санкт-Петербурге. «Сердце Техаса» - одна из групп интернет-троллей, упомянутых в недавнем обвинительном заключении специального прокурора Роберта Мюллера в отношении русских, пытающихся вмешаться в президентские выборы в США.
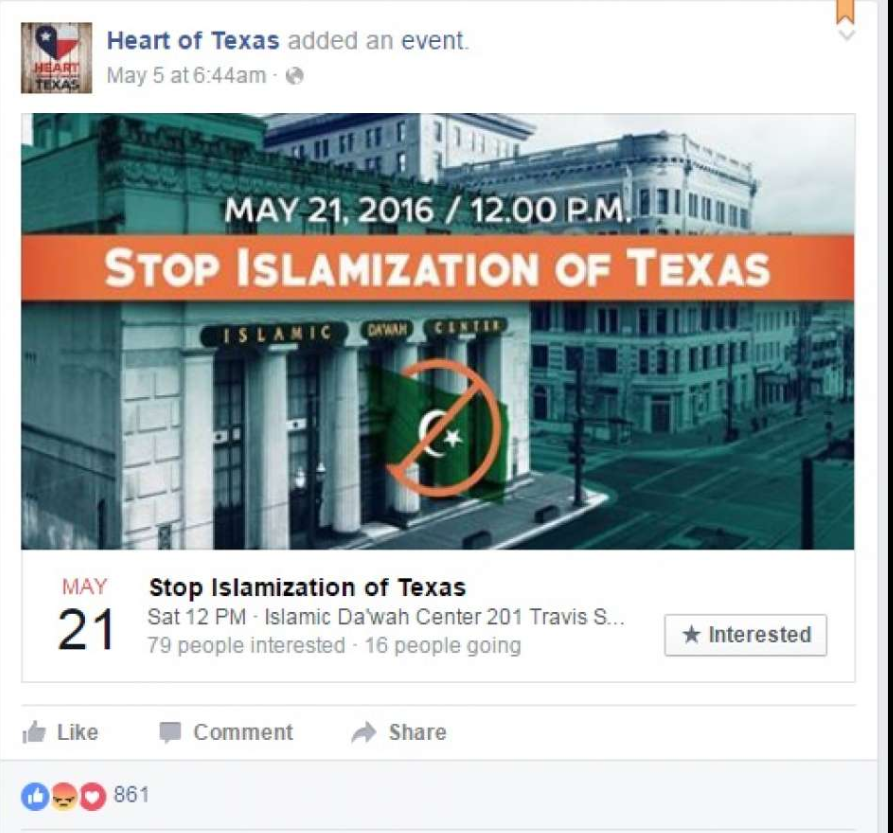
Дезинформация часто включает скоординированные кампании недостоверного поведения. Например, мошеннические аккаунты могут создать впечатление, будто многие люди придерживаются определенной точки зрения. Хотя большинству из нас нравится думать о себе как о независимом мышлении, в действительности мы эволюционировали, чтобы поддаваться влиянию других членов нашей группы и противостоять тем, кто находится в нашей группе. Обсуждения в Интернете могут повлиять на нашу точку зрения или изменить диапазон того, что мы считаем приемлемым. Люди - социальные животные, и как социальные животные мы испытываем огромное влияние окружающих нас людей. Все чаще радикализация происходит в онлайн-среде; влияние исходит от людей в виртуальном пространстве онлайн-форумов и социальных сетей.
Дезинформация с помощью автоматически сгенерированного текста является особенно важной проблемой из-за значительного расширения возможностей, предоставляемых глубоким обучением. Мы подробно обсуждаем этот вопрос, когда углубляемся в создание языковых моделей в < >.
Один из предлагаемых подходов - разработать какую-либо форму цифровой подписи, внедрить ее безупречно и создать нормы, согласно которым мы должны доверять только проверенному контенту. Глава Института ИИ Аллена Орен Эциони написал такое предложение в статье под названием «Как мы предотвратим подделку с использованием ИИ?» : «ИИ готов сделать высококачественную подделку недорогой и автоматизированной, что приведет к потенциально катастрофическим последствиям для демократии, безопасности и общества. Призрак подделки ИИ означает, что мы должны действовать, чтобы сделать цифровые подписи обязательными в качестве средства аутентификации. цифрового контента ".
Хотя мы не можем надеяться обсудить все этические вопросы, которые поднимает глубокое обучение и алгоритмы в целом, мы надеемся, что это краткое введение стало полезной отправной точкой, на которой вы можете продолжить. Теперь мы перейдем к вопросам, как определять этические проблемы и что с ними делать.
Выявление и решение этических проблем
Ошибки случаются. Их изучение и работа с ними должны быть частью дизайна любой системы, которая включает машинное обучение (и многие другие системы тоже). Проблемы, возникающие в рамках этики данных, часто бывают сложными и междисциплинарными, но очень важно, чтобы мы работали над их решением.
Так что мы можем сделать? Это большая тема, но несколько шагов к решению этических проблем:
- Проанализируйте проект, над которым вы работаете.
- Внедряйте в своей компании процессы для выявления и устранения этических рисков.
- Поддержите хорошую политику.
- Увеличивайте разнообразие.
Давайте рассмотрим каждый из этих шагов, начиная с анализа проекта, над которым вы работаете.
Анализируйте проект, над которым вы работаете
Рассматривая этические последствия своей работы, легко упустить важные моменты. Одна вещь, которая очень помогает, - это просто задавать правильные вопросы. Рэйчел Томас рекомендует учитывать следующие вопросы в процессе разработки проекта данных:
- Должны ли мы вообще это делать?
- Какая предвзятость в данных?
- Можно ли проверить код и данные?
- Какова частота ошибок для разных подгрупп?
- Какова точность простой альтернативы, основанной на правилах?
- Какие существуют процессы для рассмотрения апелляций или ошибок?
- Насколько разнообразна команда, которая его построила?
Эти вопросы могут помочь вам определить нерешенные проблемы и возможные альтернативы, которые легче понять и контролировать. Помимо правильных вопросов, важно также рассмотреть практические методы и процессы, которые необходимо внедрить.
На этом этапе следует учитывать, какие данные вы собираете и храните. Данные часто в конечном итоге используются для целей, отличных от тех, для которых они были изначально собраны. Например, IBM начала продавать продукцию нацистской Германии задолго до Холокоста, в том числе помогала в переписи населения Германии 1933 года, проведенной Адольфом Гитлером, которая была эффективна в выявлении гораздо большего числа евреев, чем ранее было признано в Германии. Точно так же данные переписи населения США использовались для облавы на американцев японского происхождения (которые были гражданами США) для интернирования во время Второй мировой войны. Важно понимать, как собранные данные и изображения могут быть использованы позже. Колумбийский профессор Тим Ву написал что «вы должны исходить из того, что любые личные данные, которые хранит Facebook или Android, - это данные, которые правительства всего мира попытаются получить или которые попытаются украсть воры».
Процессы для реализации
Центр Марккула выпустил Набор этических инструментов для практики проектирования / проектирования, который включает в себя некоторые конкретные практики для внедрения в вашей компании, в том числе регулярные плановые проверки для упреждающего поиска этических рисков (аналогично тестированию на проникновение в кибербезопасность), расширяя этический круг до учитывать точки зрения различных заинтересованных сторон и учитывать ужасных людей (как злоумышленники могут злоупотреблять, красть, неверно истолковывать, взламывать, разрушать или использовать в качестве оружия то, что вы строите?).
Даже если у вас нет разнородной команды, вы все равно можете попытаться проактивно включать точки зрения более широкой группы, учитывая такие вопросы (предоставленные Центром Марккула):
- Чьи интересы, желания, навыки, опыт и ценности мы просто приняли, а не посоветовались на самом деле?
- Кто все заинтересованные стороны, на которых напрямую повлияет наш продукт? Как были защищены их интересы? Мы спросили, как мы узнаем, каковы их интересы на самом деле?
- Кто / какие группы и отдельные лица будут косвенно затронуты в значительной степени?
- Кто может использовать этот продукт, если мы не предполагали его использовать или в целях, которые мы изначально не планировали?
Этичные линзы
Еще один полезный ресурс Центра Марккула - его Концептуальные основы технологий и инженерной практики . В нем рассматривается, как различные базовые этические линзы могут помочь в выявлении конкретных проблем, и излагаются следующие подходы и ключевые вопросы:
- Правозащитный подход: какой вариант лучше всего уважает права всех заинтересованных сторон?
- Подход справедливости :: Какой вариант относится к людям одинаково или пропорционально?
- Утилитарный подход: какой вариант принесет больше пользы и меньше всего вреда?
- Подход к общему благу: какой вариант лучше всего подходит для сообщества в целом, а не только для некоторых его членов?
- Подход добродетели :: Какой вариант заставляет меня действовать как человек, которым я хочу быть?
Рекомендации Марккулы включают более глубокое погружение в каждую из этих точек зрения, в том числе взгляд на проект через призму его последствий :
- Кого напрямую затронет этот проект? Кто пострадает косвенно?
- Скорее всего, совокупные эффекты принесут больше пользы, чем вреда, и какие виды пользы и вреда?
- Думаем ли мы обо всех соответствующих типах вреда / пользы (психологическом, политическом, экологическом, моральном, когнитивном, эмоциональном, институциональном, культурном)?
- Как этот проект может повлиять на будущие поколения?
- Риск причинения вреда от этого проекта ложится непропорционально на наименее влиятельных членов общества? Будет ли выгода непропорционально доставлена обеспеченным?
- Адекватно ли мы рассмотрели «двойное назначение»?
Альтернативой этому является деонтологическая перспектива, которая фокусируется на основных концепциях правильного и неправильного :
- Какие права других людей и обязанности по отношению к другим мы должны уважать?
- Как этот проект может повлиять на достоинство и независимость каждой заинтересованной стороны?
- Какие соображения доверия и справедливости имеют отношение к этому дизайну / проекту?
- Включает ли этот проект какие-либо противоречивые моральные обязательства перед другими или конфликтующие права заинтересованных сторон? Как мы можем расставить приоритеты?
Один из лучших способов помочь найти полные и вдумчивые ответы на подобные вопросы - убедиться, что люди, задающие вопросы, разнообразны .
Сила разнообразия
Согласно исследованию Element AI, в настоящее время менее 12% исследователей ИИ - женщины . Статистика также ужасна, когда дело касается расы и возраста. Когда все в команде имеют схожее происхождение, у них, вероятно, будут одинаковые слепые пятна в отношении этических рисков. Harvard Business Review (HBR) опубликовал ряд исследований , показавших множество преимуществ различных команд, в том числе:
- «Как разнообразие может стимулировать инновации»
- «Команды быстрее решают проблемы, когда они более разнообразны»
- «Почему разные команды умнее» и
- «Защитите свое исследование: что делает команду умнее? Больше женщин»
Разнообразие может привести к раннему выявлению проблем и рассмотрению более широкого круга решений. Например, Трейси Чоу была одним из первых инженеров Quora. Она рассказала о своем опыте , описывая, как она внутренне ратовала за добавление функции, которая позволила бы блокировать троллей и других злоумышленников. Чжоу вспоминает: «Я очень хотел работать над этой функцией, потому что я лично чувствовал неприязнь и оскорбление на сайте (пол не является маловероятной причиной того, почему) ... Но если бы у меня не было этой личной точки зрения, это возможно что команда Quora не стала бы уделять приоритетное внимание созданию кнопки-блока на столь раннем этапе своего существования ». Преследования часто вынуждают людей из маргинализированных групп уходить с онлайн-платформ, поэтому эта функция важна для поддержания здоровья сообщества Quora.
По данным Harvard Business Review, важно понимать, что женщины покидают технологическую отрасль более чем в два раза чаще, чем мужчины (41% женщин, работающих в техническом отпуске, по сравнению с 17% мужчин). Анализ более 200 книг, официальных документов и статей показал, что причина их ухода в том, что «с ними обращаются несправедливо; им недоплачивают, меньше шансов получить ускоренную работу, чем их коллегам-мужчинам, и они не могут продвигаться по службе ».
Исследования подтвердили ряд факторов, затрудняющих продвижение женщин на рабочем месте. Женщины получают более расплывчатую обратную связь и личную критику при оценке работы, тогда как мужчины получают действенные советы, связанные с бизнес-результатами (что более полезно). Женщины часто лишаются возможности выполнять более творческие и новаторские роли и не получают заметных «сложных» заданий, которые помогают продвинуться по службе. Одно исследование показало, что мужские голоса воспринимаются как более убедительные, основанные на фактах и логические, чем женские голоса, даже при чтении идентичных сценариев.
Статистически доказано, что получение наставничества помогает продвигаться вперед мужчинам, но не женщинам. Причина этого в том, что когда женщины получают наставничество, это совет о том, как им следует измениться и получить больше самопознания. Когда мужчины получают наставничество, это публичное признание их авторитета. Угадайте, что более полезно для продвижения по службе?
До тех пор, пока квалифицированные женщины продолжают бросать работу в сфере технологий, обучение большего числа девочек программированию не решит проблем разнообразия, преследующих эту отрасль. Инициативы по разнообразию часто в конечном итоге сосредоточены в первую очередь на белых женщинах, хотя цветные женщины сталкиваются с множеством дополнительных препятствий. В ходе интервью с 60 цветными женщинами, работающими в исследованиях STEM, 100% из них испытали дискриминацию.
Процесс найма особенно нарушен в технологиях. Одно исследование, указывающее на эту дисфункцию, было проведено Triplebyte, компанией, которая помогает нанимать инженеров-программистов в компании, проводя стандартизированное техническое интервью как часть этого процесса. У них есть увлекательный набор данных: результаты того, как более 300 инженеров сдали экзамен, а также результаты того, как эти инженеры сделали во время собеседования для различных компаний. Вывод номер один из исследования Triplebyte заключается в том, что «типы программистов, которых ищет каждая компания, часто имеют мало общего с тем, что ей нужно или что она делает. Скорее, они отражают культуру компании и прошлое основателей ».
Это вызов для тех, кто пытается прорваться в мир глубокого обучения, поскольку сегодня группы глубокого обучения в большинстве компаний были созданы учеными. Эти группы склонны искать людей, «похожих на них», то есть людей, которые могут решать сложные математические задачи и понимать сложный жаргон. Они не всегда знают, как определить людей, которые действительно умеют решать реальные проблемы с помощью глубокого обучения.
Это оставляет большие возможности для компаний, которые готовы выйти за рамки статуса и происхождения и сосредоточиться на результатах!
Справедливость, подотчетность и прозрачность
Профессиональное сообщество компьютерных ученых, ACM, проводит конференцию по этике данных, которая называется Конференция по справедливости, подотчетности и прозрачности. «Справедливость, подотчетность и прозрачность» , которая используется для перехода под аббревиатурой FAT , но теперь использует для менее неугодного FAccT . В Microsoft есть группа по теме «Справедливость, подотчетность, прозрачность и этика» (FATE). В этом разделе мы будем использовать «FAccT» для обозначения концепций справедливости, подотчетности и прозрачности .
FAccT - еще один объектив, который может оказаться полезным при рассмотрении этических вопросов. Одним из полезных ресурсов для этого является бесплатная онлайн-книга Справедливость и машинное обучение:ограничения и возможности.Солона Барокаса, Морица Хардта и Арвинда Нараянана, который «дает взгляд на машинное обучение, в котором справедливость рассматривается как центральная проблема, а не второстепенная задача». Однако он также предупреждает, что он «намеренно ограничен по своему охвату ... Узкая формулировка этики машинного обучения может быть соблазнительной для технологов и предприятий как способ сосредоточиться на технических вмешательствах, избегая более глубоких вопросов о власти и подотчетности. против этого искушения ". Вместо того, чтобы давать обзор подхода FAccT к этике (что лучше сделать в таких книгах, как эта), мы сосредоточимся здесь на ограничениях такого рода узких рамок.
Отличный способ определить, является ли этическая линза законченной, - это попытаться привести пример, в котором линза и наша собственная этическая интуиция дают разные результаты. Ос Киз, Джеван Хатсон и Мередит Дурбин исследовали это наглядно в своей статье «Предложение по мульчированию: анализ и улучшение алгоритмической системы для превращения пожилых людей в жидкую суспензию с высоким содержанием питательных веществ» . В аннотации к статье говорится:
: Этические последствия алгоритмических систем много обсуждались как в HCI, так и в более широком сообществе тех, кто интересуется технологическим проектированием, разработкой и политикой. В этой статье мы исследуем применение одной известной этической основы - справедливости, подотчетности и прозрачности - к предлагаемому алгоритму, который решает различные социальные проблемы, связанные с продовольственной безопасностью и старением населения. Используя различные стандартизированные формы алгоритмического аудита и оценки, мы резко повышаем соответствие алгоритма структуре FAT, что приводит к созданию более этичной и полезной системы. Мы обсуждаем, как это может послужить руководством для других исследователей или практиков, стремящихся обеспечить лучшие этические результаты от алгоритмических систем в своей работе.
В этой статье, довольно спорное предложение ( «Включение пожилых людей в высоком питательное вещество шламового») и результаты ( «резко повысить приверженность алгоритма в рамки FAT, что приводит к более этической и благотворной системе») в ладах .. мягко говоря!
В философии, и особенно в философии этики, это один из самых эффективных инструментов: во-первых, нужно придумать процесс, определение, набор вопросов и т. Д., Который предназначен для решения некоторой проблемы. Затем попробуйте придумать пример, в котором это очевидное решение приводит к предложению, которое никто не сочтет приемлемым. Затем это может привести к дальнейшему уточнению решения.
Пока что мы сосредоточились на том, что можете делать вы и ваша организация. Но иногда индивидуальных или организационных действий недостаточно. Иногда правительствам также необходимо учитывать последствия для политики.
Роль политики
Мы часто разговариваем с людьми, которые хотят, чтобы технические или дизайнерские исправления стали полным решением тех проблем, которые мы обсуждали; например, технический подход к дебиазным данным или рекомендации по разработке, позволяющие сделать технологию менее захватывающей. Хотя такие меры могут быть полезными, их будет недостаточно для решения основных проблем, которые привели к нашему нынешнему состоянию. Например, до тех пор, пока невероятно выгодно создавать вызывающие привыкание технологии, компании будут продолжать делать это, независимо от того, имеет ли это побочный эффект продвижения теорий заговора и загрязнения нашей информационной экосистемы. Хотя отдельные дизайнеры могут попытаться настроить дизайн продукта, мы не увидим существенных изменений, пока не изменятся основные стимулы для получения прибыли.
Эффективность регулирования
Чтобы понять, что может побудить компании к конкретным действиям, рассмотрим следующие два примера поведения Facebook. В 2018 году расследование ООН показало, что Facebook сыграл «определяющую роль» в продолжающемся геноциде рохинджа, этнического меньшинства в Минамаре, которое Генеральный секретарь ООН Антониу Гутерриш назвал «одним из, если не самым, дискриминируемым народом в мире». мир." Местные активисты предупреждали руководителей Facebook о том, что их платформа используется для распространения разжигающих ненависть высказываний и подстрекательства к насилию еще с 2013 года. В 2015 году их предупредили, что Facebook может играть в Мьянме ту же роль, что и радиопередачи во время геноцида в Руанде. (где погиб миллион человек). Однако к концу 2015 года Facebook нанял только четырех подрядчиков, говорящих на бирманском языке. Как сказал один человек, близкий к делу: «Это не ретроспективный взгляд на 20/20. Масштаб этой проблемы был значительным, и он уже был очевиден». Цукерберг пообещал во время слушаний в Конгрессе нанять «десятки» для решения проблемы геноцида в Мьянме (в 2018 году, спустя годы после начала геноцида, включая уничтожение огнем по крайней мере 288 деревень в северном штате Ракхайн после августа 2017 года).
Это резко контрастирует с тем, что Facebook быстро нанял 1200 человек в Германии, чтобы попытаться избежать дорогостоящих штрафов (до 50 миллионов евро) в соответствии с новым немецким законом против языка вражды. Очевидно, что в этом случае Facebook больше отреагировал на угрозу финансового штрафа, чем на систематическое уничтожение этнического меньшинства.
В статье о проблемах конфиденциальности Мацей Цегловски проводит параллели с движением за защиту окружающей среды:
: Этот нормативный проект был настолько успешным в Первом мире, что мы рискуем забыть, какой была жизнь до него. Удушающий смог, от которого сегодня гибнут тысячи людей в Джакарте и Дели, был https://en.wikipedia.org/wiki/Pea_soup_fog[икогда символом Лондона]. Река Кайахога в Огайо http://www.ohiohistorycentral.org/w/Cuyahoga_River_Fire [ надежно загорелась]. В особенно ужасающем примере непредвиденных последствий, тетраэтилсвинец добавлен в бензин https://en.wikipedia.org/wiki/Lead%E2%80%93crime_hypothesis[raisedуровень насильственных преступлений] во всем мире за пятьдесят лет. Ни один из этих вредов нельзя было устранить, говоря людям голосовать кошельком, или тщательно пересматривая экологическую политику каждой компании, которой они передали свой бизнес, или прекратить использование рассматриваемых технологий. Чтобы их исправить, требовалось скоординированное, а иногда и весьма техническое регулирование, выходящее за рамки юрисдикции. В некоторых случаях, как, например, https://en.wikipedia.org/wiki/Montreal_Protocol [запрет на коммерческие хладагенты], который разрушает озоновый слой, это постановление требовало всемирного консенсуса. Мы находимся на той стадии, когда нам необходимо аналогичное изменение взглядов на наш закон о конфиденциальности.
Права и политика
Чистый воздух и чистая питьевая вода - это общественные блага, которые практически невозможно защитить с помощью индивидуальных рыночных решений, они требуют согласованных регулирующих действий. Точно так же многие вреды, возникающие в результате непреднамеренных последствий неправильного использования технологий, связаны с общественными благами, такими как загрязненная информационная среда или ухудшение внешней конфиденциальности. Слишком часто неприкосновенность частной жизни оформляется как личное право, тем не менее широкое слежение оказывает влияние на общество (что все равно имело бы место, даже если бы несколько человек могли отказаться от этого).
Многие из проблем, которые мы наблюдаем в сфере технологий, на самом деле являются проблемами прав человека, например, когда предвзятый алгоритм рекомендует черным обвиняемым иметь более длительные сроки тюремного заключения, когда определенные объявления о вакансиях показываются только молодым людям или когда полиция использует распознавание лиц для выявления протестующих. . Подходящим местом для рассмотрения вопросов прав человека обычно является закон.
Нам нужны как нормативные, так и правовые изменения, а также этическое поведение людей. Изменение индивидуального поведения не может повлиять на несоответствие стимулов к прибыли, внешние эффекты (когда корпорации получают большую прибыль, перекладывая свои издержки и вред на общество в целом) или системные неудачи. Однако закон никогда не будет охватывать все крайние случаи, и важно, чтобы отдельные разработчики программного обеспечения и специалисты по обработке данных были оснащены необходимыми средствами для принятия этических решений на практике.
Машины: исторический прецедент
Проблемы, с которыми мы сталкиваемся, сложны, и простых решений нет. Это может обескураживать, но мы находим надежду при рассмотрении других серьезных проблем, с которыми люди сталкивались на протяжении всей истории. Одним из примеров является движение за повышение безопасности автомобилей, описанное в качестве тематического исследования в « Таблицах данных для наборов данных» Тимнитом Гебру и др. а в дизайнерском подкасте 99% Invisible. У ранних автомобилей не было ремней безопасности, металлических ручек на приборной панели, которые могли застрять в черепах людей во время аварии, обычных стеклянных окон, которые разбивались опасным образом, и неразборных рулевых колонок, которые пронзали водителей. Однако автомобильные компании невероятно сопротивлялись даже обсуждению идеи безопасности как того, чем они могли бы помочь, и широко распространено было мнение, что автомобили такие, какие они есть, и что именно люди, которые их используют, создают проблемы.
Активистам в области безопасности потребителей и защитникам потребовались десятилетия работы, чтобы даже изменить общенациональный разговор, чтобы учесть, что, возможно, автомобильные компании несут некоторую ответственность, которую следует решать посредством регулирования. Когда была изобретена складная рулевая колонка, она не применялась в течение нескольких лет, так как не было финансовых стимулов для этого. Крупная автомобильная компания General Motors наняла частных детективов, чтобы попытаться раскопать компромат на защитника интересов потребителей Ральфа Надера. Требование наличия ремней безопасности, манекенов для краш-тестов и складных рулевых колонок было большим успехом. Только в 2011 году автомобильные компании были вынуждены начать использовать манекены для краш-тестов, которые представляли бы тела средней женщины, а не только среднего мужчины; до этого вероятность получить травму в автокатастрофе с таким же ударом у женщин на 40% выше, чем у мужчин.
Вывод
Исходя из опыта работы с бинарной логикой, отсутствие четких этических ответов поначалу может расстраивать. Тем не менее, последствия того, как наша работа влияет на мир, в том числе непредвиденные последствия и превращение работы в оружие со стороны злоумышленников, являются одними из наиболее важных вопросов, которые мы можем (и должны!) Рассмотреть. Несмотря на то, что нет простых ответов, есть определенные подводные камни, которых следует избегать, и методы, которым следует следовать, чтобы двигаться к более этичному поведению.
Многие люди (в том числе и мы!) Ищут более убедительные и надежные ответы о том, как бороться с вредным воздействием технологий. Однако, учитывая сложный, далеко идущий и междисциплинарный характер стоящих перед нами проблем, простых решений не существует. Джулия Ангвин, бывший старший репортер ProPublica, которая занимается проблемами алгоритмической предвзятости и слежки (и одна из исследователей алгоритма рецидивизма COMPAS в 2016 году, который помог зажечь поле FAccT), сказала в интервью 2019 года :
: Я твердо верю, что для решения проблемы необходимо ее диагностировать, и что мы все еще находимся на этапе диагностики. Если вы думаете о начале веков и индустриализации, у нас было, я не знаю, 30 лет детского труда, неограниченные часы работы, ужасные условия труда, и потребовалось немало журналистских разоблачений и пропаганды, чтобы диагностировать проблему и иметь некоторое понимание того, что это было, а затем активизм, чтобы изменить законы. Я чувствую, что мы находимся во второй индустриализации информации о данных ... Я вижу свою роль в том, чтобы как можно более четко прояснить, в чем заключаются недостатки, и действительно точно диагностировать их, чтобы их можно было решить. Это тяжелая работа, и ей нужно заниматься гораздо больше людей.
Обнадеживает то, что Ангвин считает, что мы в значительной степени все еще находимся на стадии диагностики: если вы чувствуете неполное понимание этих проблем, это нормально и естественно. Пока ни у кого нет «лекарства», хотя жизненно важно, чтобы мы продолжали работать, чтобы лучше понять и решить проблемы, с которыми мы сталкиваемся.
Один из рецензентов этой книги, Фред Монро, раньше работал в сфере торговли хедж-фондами. После прочтения этой главы он сказал нам, что многие из обсуждаемых здесь вопросов (распределение данных резко отличается от того, на котором была обучена модель, петли обратной связи по влиянию на модель после развертывания и в масштабе и т. Д.), Также были ключевые вопросы для построения прибыльных торговых моделей. То, что вам нужно делать для рассмотрения социальных последствий, будет во многом совпадать с тем, что вам нужно делать для рассмотрения организационных, рыночных и потребительских последствий, поэтому тщательное размышление об этике также может помочь вам тщательно подумать о том, как сделайте ваш информационный продукт успешным в целом!
Опросник
- Предоставляет ли этика список «правильных ответов»?
- Как работа с людьми разного происхождения может помочь при рассмотрении этических вопросов?
- Какую роль играла IBM в нацистской Германии? Почему компания участвовала именно так? Почему участвовали рабочие?
- Какова была роль первого человека, заключенного в тюрьму в дизельном скандале с Volkswagen?
- В чем заключалась проблема с базой данных о предполагаемых членах банды, которую ведут сотрудники правоохранительных органов Калифорнии?
- Почему алгоритм рекомендаций YouTube рекомендовал педофилам видео с частично одетыми детьми, хотя ни один сотрудник Google не запрограммировал эту функцию?
- Какие проблемы с центральностью метрик?
- Почему Meetup.com не включил гендер в свою систему рекомендаций для технических встреч?
- Каковы шесть типов предвзятости в машинном обучении, согласно Сурешу и Гуттагу?
- Приведите два примера исторической расовой предвзятости в США.
- Откуда больше всего изображений в ImageNet?
- В статье «Автоматизирует ли машинное обучение моральные опасности и ошибки», почему синусит является предиктором инсульта?
- Что такое предвзятость представления?
- Чем машины и люди отличаются друг от друга с точки зрения их использования для принятия решений?
- Дезинформация - это то же самое, что «фейковые новости»?
- Почему дезинформация с помощью автоматически сгенерированного текста является особенно важной проблемой?
- Какие пять этических линз описывает Центр Марккула?
- Где политика является подходящим инструментом для решения проблем этики данных?
Дальнейшие исследования:
- Прочтите статью «Что происходит, когда алгоритм подрывает ваше здоровье». Как можно было избежать подобных проблем в будущем?
- Изучите, чтобы узнать больше о системе рекомендаций YouTube и ее влиянии на общество. Как вы думаете, в рекомендательных системах всегда должны быть петли обратной связи с отрицательными результатами? Какие подходы Google может предпринять, чтобы их избежать? А что с правительством?
- Прочтите статью «Дискриминация при размещении рекламы в Интернете» . Как вы думаете, следует ли считать Google ответственным за то, что случилось с доктором Суини? Что было бы подходящим ответом?
- Как междисциплинарная команда может помочь избежать негативных последствий?
- Прочтите статью «Автоматизирует ли машинное обучение моральные опасности и ошибки». Какие действия, по вашему мнению, следует предпринять для решения проблем, обозначенных в этом документе?
- Прочтите статью «Как предотвратить подделку с использованием искусственного интеллекта?» Как вы думаете, может ли предложенный подход Эциони сработать? Почему?
- Заполните раздел «Анализ проекта, над которым вы работаете» в этой главе.
- Подумайте, может ли ваша команда быть более разнообразной. Если да, то какие подходы могут помочь?
Глубокое обучение на практике: готово!
Поздравляю! Вы дочитали до конца первого раздела книги. В этом разделе мы попытались показать вам, на что способно глубокое обучение, и как вы можете использовать его для создания реальных приложений и продуктов. На этом этапе вы получите гораздо больше от книги, если потратите некоторое время на то, чтобы попробовать то, что вы узнали. Возможно, вы уже делали это по ходу дела - в этом случае отлично! Если нет, то это тоже не проблема ... Сейчас прекрасное время, чтобы начать экспериментировать.
Если вы еще не были на сайте книги, зайдите туда сейчас. Очень важно подготовиться к работе с ноутбуками. Чтобы стать эффективным специалистом по глубокому обучению, нужно практиковаться, поэтому вы должны быть обучающими моделями. Так что, пожалуйста, запустите ноутбуки, если вы еще этого не сделали! А также посмотрите на веб-сайт любые важные обновления или уведомления; глубокое обучение меняется быстро, и мы не можем изменить слова, напечатанные в этой книге, поэтому вам нужно искать веб-сайт, чтобы убедиться, что у вас есть самая последняя информация.
Убедитесь, что вы выполнили следующие шаги:
- Подключитесь к одному из серверов GPU Jupyter, рекомендованных на сайте книги.
- Самостоятельно запустить первую записную книжку.
- Загрузите изображение, которое найдете в первой записной книжке; затем попробуйте несколько разных изображений, чтобы увидеть, что происходит.
- Запустите вторую записную книжку, собрав собственный набор данных на основе заданных вами поисковых запросов по изображениям.
- Подумайте о том, как вы можете использовать глубокое обучение, чтобы помочь вам в ваших собственных проектах, в том числе о том, какие типы данных вы могли бы использовать, какие проблемы могут возникнуть и как вы могли бы смягчить эти проблемы на практике.
В следующем разделе книги вы узнаете, как и почему работает глубокое обучение, вместо того, чтобы просто увидеть, как его можно использовать на практике. Понимание того, как и почему важно как для практиков, так и для исследователей, потому что в этой довольно новой области почти каждый проект требует определенного уровня настройки и отладки. Чем лучше вы понимаете основы глубокого обучения, тем лучше будут ваши модели. Эти основы менее важны для руководителей, менеджеров по продуктам и т. Д. (Хотя все еще полезны, поэтому не стесняйтесь читать дальше!), Но они критически важны для любого, кто на самом деле обучает и самостоятельно развертывает модели.
Метки


Раскрыть комментарии 0
Чтобы оставить комментарий , Вам необходимо Авторизоваться или пройти Регистрацию