
#hide
!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()#hide
from fastbook import *Другие проблемы компьютерного зрения
В предыдущей главе вы узнали несколько важных практических приемов обучения моделей.Выбор скорости обучения и количества эпох, очень важны для получения хороших результатов.
В этой главе мы рассмотрим два других типа проблем компьютерного зрения: классификацию с несколькими метками и регрессию. Первый - когда требуется спрогнозировать более одной метки на изображение (или иногда вообще ни одной), а второй - когда метки представляют собой одно или несколько чисел - количество вместо категории.
В этом процессе будут более глубоко изучены функции активации, цели и потери выходных данных в моделях глубокого обучения.
Классификация по нескольким меткам
Многометочная классификация относится к проблеме идентификации категорий объектов на изображениях, которые могут не содержать один тип объекта. Возможно, существует несколько типов объектов или вообще нет объектов в искомых классах.
Одна из проблем с классификатором медведей, который мы развернули в<>, заключалась в том, что если пользователь загружал что-то, что не было никаким медведем, модель все равно говорила, что это был либо гризли, либо черный, либо плюшевый медведь - она не могла предсказать "совсем не медведь". На самом деле, после того, как мы закончим эту главу, вам будет полезно вернуться к вашему приложению - классификатору изображений и попытаться переучить его с помощью метода нескольких меток, а затем протестировать его, передав изображение, которое не относится ни к одному из ваших классов.
Мы не встречали много примеров, когда люди обучали мультиметочные (multi-label) классификаторы, но мы очень часто видим, как пользователи и разработчики жалуются на эту проблему. Похоже, что это простое решение совсем не понимается и не ценится! На практике чаще встречаются изображения с нулевым совпадением или более чем одним совпадением, мы, вероятно, должны были ожидать, что классификаторы с несколькими метками будут применяться значительно чаще, чем классификаторы с одной меткой.Но это не так.
Сначала давайте посмотрим, как выглядит набор данных с несколькими метками, а затем объясним, как подготовить его для нашей модели. Вы увидите, что архитектура модели не изменилась по сравнению с предыдущей главой, изменилась только функция потерь. Начнем с данных.
Данные
В нашем примере мы собираемся использовать набор данных PASCAL, который может классифицировать изображение несколькими классами. Как обычно начнем с загрузки и извлечения набора данных :
from fastai.vision.all import *
path = untar_data(URLs.PASCAL_2007)Этот набор данных отличается от тех, которые мы видели раньше, тем, что он не структурирован по имени файла или папке, а вместо этого поставляется с файлом CSV (значения, разделенные запятыми), в котором описано, какие метки использовать для каждого изображения. Мы можем проверить CSV-файл, прочитав его в Pandas DataFrame:
df = pd.read_csv(path/'train.csv')
df.head()| fname | labels | is_valid | |
|---|---|---|---|
| 0 | 000005.jpg | chair | True |
| 1 | 000007.jpg | car | True |
| 2 | 000009.jpg | horse person | True |
| 3 | 000012.jpg | car | False |
| 4 | 000016.jpg | bicycle | True |
Как видно, список категорий для каждого изображения отображается в виде строки, разделенной пробелами.
Боковая панель: Pandas и фреймы данных
Нет, на самом деле это не панда! Pandas - это библиотека Python, которая используется для обработки и анализа табличных данных и данных временных рядов. Основной класс DataFrame представляет собой таблицу строк и столбцов. Вы можете получить DataFrame из файла CSV, таблицы базы данных, словарей Python и многих других источников. В Jupyter DataFrame выводится в виде отформатированной таблицы, как показано здесь.
Вы можете получить доступ к строкам и столбцам DataFrame с помощью iloc свойства, как если бы это была матрица:
df.iloc[:,0]0 000005.jpg
1 000007.jpg
2 000009.jpg
3 000012.jpg
4 000016.jpg
...
5006 009954.jpg
5007 009955.jpg
5008 009958.jpg
5009 009959.jpg
5010 009961.jpg
Name: fname, Length: 5011, dtype: object
df.iloc[0,:]
# `:` всегда необязательны (в numpy, pytorch, pandas, etc.),
# таким образом, это эквивалентно:
df.iloc[0]fname 000005.jpg labels chair is_valid True Name: 0, dtype: object
Вы также можете получить столбец по имени путем непосредственной индексации в DataFrame:
df['fname']0 000005.jpg
1 000007.jpg
2 000009.jpg
3 000012.jpg
4 000016.jpg
...
5006 009954.jpg
5007 009955.jpg
5008 009958.jpg
5009 009959.jpg
5010 009961.jpg
Name: fname, Length: 5011, dtype: object
Вы можете создавать новые столбцы и выполнять вычисления с использованием столбцов:
tmp_df = pd.DataFrame({'a':[1,2], 'b':[3,4]})
tmp_df| a | b | |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 2 | 4 |
tmp_df['c'] = tmp_df['a']+tmp_df['b']
tmp_df| a | b | c | |
|---|---|---|---|
| 0 | 1 | 3 | 4 |
| 1 | 2 | 4 | 6 |
Pandas - это быстрая и гибкая библиотека, которая является важной частью набора инструментов Python для каждого специалиста по данным. К сожалению, его API может сбивать с толку и удивлять, поэтому нужно время, чтобы с ним познакомиться. Если вы раньше не использовали Pandas, мы рекомендуем пройти обучение; нам особенно нравится книга « Python для анализа данных » Уэса МакКинни, создателя Pandas (О'Рейли). Он также охватывает другие важные библиотеки, такие как matplotlib и numpy. Мы постараемся кратко описать функциональность Pandas, которую мы используем, но не будем вдаваться в детали книги МакКинни.
Конечная боковая панель
Теперь, когда мы увидели, как выглядят данные, давайте подготовим их для обучения модели.
Создание блока данных
Как преобразовать DataFrame объект в DataLoaders объект? Обычно мы рекомендуем использовать API блока данных для создания DataLoaders объекта, где это возможно, поскольку он обеспечивает хорошее сочетание гибкости и простоты. Здесь мы покажем вам шаги, которые мы предпринимаем, чтобы использовать API блоков данных для создания DataLoadersобъекта на практике, используя этот набор данных в качестве примера.
Как мы видели, PyTorch и fastai имеют два основных класса для представления и доступа к обучающему или проверочному набору:
- Dataset :: Коллекция, которая возвращает кортеж вашей независимой (x) и зависимой переменной (y) для одного элемента.
- DataLoader :: Итератор, который предоставляет поток мини-пакетов, где каждый мини-пакет представляет собой кортеж из пакета независимых переменных (x) и зависимых (y) переменных.
Вдобавок к этому fastai предоставляет два класса для объединения ваших тренировочных и проверочных наборов:
- Datasets:: Объект, содержащий обучающий и проверочный набор данных
- DataLoaders:: Объект, содержащий обучающий и проверочный DataLoader
Поскольку DataLoader строится поверх a Dataset и добавляет к нему дополнительные функции (объединение нескольких элементов в мини-пакет), часто проще всего начать с создания и тестирования Datasets, а затем посмотреть, как работает DataLoaders.
Когда мы создаем DataBlock, мы наращиваем его постепенно, шаг за шагом. Это отличный способ чтобы не упустить из виду любые проблемы во время кодирования.Если возникает проблема, то она находится в строке кода, который вы только что набрали!
Начнем с простейшего случая, который представляет собой блок данных, созданный без параметров:
dblock = DataBlock()Из этого можно создать объект Datasets. Единственное, что нужно, это источник - в данном случае, наш DataFrame:
dsets = dblock.datasets(df)Он содержит обучающий и проверочный набор данных, которые мы можем проиндексировать:
len(dsets.train),len(dsets.valid)(4009, 1002)
x,y = dsets.train[0]
x,y(fname 008663.jpg labels car person is_valid False Name: 4346, dtype: object, fname 008663.jpg labels car person is_valid False Name: 4346, dtype: object)
Как видно, дважды возвращается строка DataFrame.Потому, что по умолчанию блок данных предполагает, что у нас есть две вещи: вход и цель. Мы должны взять соответствующие поля из DataFrame и передать их методам DataBlock - get_x и get_y :
x['fname']'008663.jpg'
dblock = DataBlock(get_x = lambda r: r['fname'], get_y = lambda r: r['labels'])
dsets = dblock.datasets(df)
dsets.train[0]('005620.jpg', 'aeroplane')
Как вы видите, вместо определения функции обычным способом мы используем ключевое слово лямбда (lambda) Python. Это всего лишь ярлык для определения и последующего обращения к функции. Следующий более подробный подход идентичен:
def get_x(r): return r['fname']
def get_y(r): return r['labels']
dblock = DataBlock(get_x = get_x, get_y = get_y)
dsets = dblock.datasets(df)
dsets.train[0]('002549.jpg', 'tvmonitor')
Лямбда-функции отлично подходят для быстрой итерации, но они несовместимы с сериализацией, поэтому мы советуем вам использовать более подробный подход, если вы хотите экспортировать свой Learner после обучения (лямбда-выражения подходят, если вы просто экспериментируете).
Мы видим, что независимую переменную (x) необходимо преобразовать в полный путь, чтобы мы могли открыть ее как изображение, а зависимую переменную нужно будет разделить на символ пробела (который используется по умолчанию для функции Python split ), чтобы она стала списком:
def get_x(r): return path/'train'/r['fname']
def get_y(r): return r['labels'].split(' ')
dblock = DataBlock(get_x = get_x, get_y = get_y)
dsets = dblock.datasets(df)
dsets.train[0](Path('/home/user/.fastai/data/pascal_2007/train/002844.jpg'), ['train'])
Чтобы действительно открыть изображение и выполнить преобразование в тензоры, нам нужно будет использовать набор преобразований. Мы можем использовать те же типы блоков, что и раньше, за одним исключением: ImageBlock снова будет работать нормально, потому что у нас есть путь, который указывает на допустимое изображение, но CategoryBlock не будет работать. Проблема в том, что блок возвращает одно целое число, но нам нужно иметь возможность иметь несколько меток для каждого элемента. Чтобы решить эту проблему, мы используем MultiCategoryBlock. Этот тип блока ожидает получения списка строк, как в нашем случае, поэтому давайте проверим его:
dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
get_x = get_x, get_y = get_y)
dsets = dblock.datasets(df)
dsets.train[0](PILImage mode=RGB size=500x375, TensorMultiCategory([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.]))
Как видите, наш список категорий не закодирован так, как это было обычно в CategoryBlock. Раньше у нас было одно целое число, представляющее, какая категория присутствует, в зависимости от ее местоположения в нашем словаре. Сейчас у нас есть список нулей, с единицей в любой позиции, где присутствует эта категория. Например, если на второй и четвертой позициях стоит единица, это означает, что это изображение относиться ко второй и четвертый категории из нашего словаря. Это называется горячим кодированием (One-Hot Encoding). Причина, по которой мы не можем просто использовать список индексов категорий, заключается в том, что каждый список будет иметь разную длину, а PyTorch требует тензоров одинаковой длины.
жаргон: One-hot encoding: использование вектора нулей с единицей в каждом месте, которое представлено в данных.
Давайте проверим, что представляют собой категории в этом примере (мы используем удобную torch.where функцию, которая сообщает нам все индексы, где наше условие истинно или ложно):
idxs = torch.where(dsets.train[0][1]==1.)[0]
dsets.train.vocab[idxs](#1) ['dog']
С массивами NumPy, тензорами PyTorch и L классом fastai мы можем индексировать непосредственно с помощью списка или вектора, что делает большую часть кода (например, в этом примере) более ясной и лаконичной.
До сих пор мы игнорировали столбец is_valid, что означает, что DataBlock использует разделение по умолчанию. Чтобы явно выбрать элементы нашего проверочного набора, нам нужно записать функцию и передать ее splitter (или использовать одну из предопределенных функций или классов fastai).Он примет элементы (здесь весь наш DataFrame) и должен вернуть два (или более) списка целых чисел:
def splitter(df):
train = df.index[~df['is_valid']].tolist()
valid = df.index[df['is_valid']].tolist()
return train,valid
dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
splitter=splitter,
get_x=get_x,
get_y=get_y)
dsets = dblock.datasets(df)
dsets.train[0](PILImage mode=RGB size=500x333, TensorMultiCategory([0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]))
DataLoader собирает элементы из Dataset в мини-партию. Это кортеж тензоров, где каждый тензор просто укладывает элементы из этого местоположения в элемент Dataset. Теперь, когда мы убедились, что отдельные элементы выглядят нормально, нам нужно сделать еще один шаг, чтобы убедиться, что мы можем создать свои DataLoaders, а именно убедиться, что каждый элемент имеет одинаковый размер. Для этого мы можем использовать RandomResizedCrop:
dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
splitter=splitter,
get_x=get_x,
get_y=get_y,
item_tfms = RandomResizedCrop(128, min_scale=0.35))
dls = dblock.dataloaders(df)И теперь мы можем показать образец наших данных:
dls.show_batch(nrows=1, ncols=3)
Помните, что если при создании DataLoaders из DataBlock происходит что-то не так, или если необходимо просмотреть, что именно происходит с DataBlock, можно использовать метод summary, представленный в последней главе.
Теперь наши данные готовы для обучения модели. Ничего не изменилось, при создании Learner, но за кулисами, библиотека fastai выбрала для нас новую функцию потерь: двоичную кросс-энтропию.
Двоичная кросс-энтропия
Теперь создадим наш Learner. В < > мы видели, что Learnerобъект содержит четыре основных элемента: модель, объект DataLoaders, оптимизатор и используемую функцию потери. У нас уже есть DataLoaders, мы можем использовать модели resnet Fastai (которые мы позже научимся создавать с нуля ), и мы знаем, как создать оптимизатор SGD. Сосредоточимся на том, чтобы у нас была подходящая функция потерь. Для этого мы используем cnn_learner для создания Learner, чтобы посмотреть на его активации:
learn = cnn_learner(dls, resnet18)Мы также видели, что модель Learner, как правило, является объектом класса, наследуемого от nn.Module, и что мы можем вызывать его, используя круглые скобки, и он вернет активации модели. Вы должны передать ему свою независимую переменную в виде мини-пакета.Мы можем попробовать это, взяв мини-пакет из нашего DataLoaderи передав его модели:
x,y = to_cpu(dls.train.one_batch())
activs = learn.model(x)
activs.shapetorch.Size([64, 20])
Подумайте, почему activs имеют такую форму - у нас размер партии 64, и нам нужно вычислить вероятность каждой из 20 категорий. Вот как выглядит одна из этих активаций:
activs[0]tensor([ 0.7476, -1.1988, 4.5421, -1.5915, -0.6749, 0.0343, -2.4930, -0.8330, -0.3817, -1.4876, -0.1683, 2.1547,
-3.4151, -1.1743, 0.1530, -1.6801, -2.3067, 0.7063, -1.3358, -0.3715],
grad_fn=<SelectBackward>)
Примечание. Получение активаций модели. Знание того, как вручную получить мини-партию и передать ее в модель, а также посмотреть на активацию и потерю, действительно важно для отладки вашей модели. Это также очень полезно для обучения, то что вы можете видеть, что происходит.
Они еще не масштабированы между 0 и 1, но мы научились делать это в < >, используя сигмоидальную функцию. Мы также видели, как вычислить потери на основе этого - это наша функция потерь от < >, с добавлением log как обсуждалось в предыдущей главе:
def binary_cross_entropy(inputs, targets):
inputs = inputs.sigmoid()
return -torch.where(targets==1, 1-inputs, inputs).log().mean()Обратите внимание: поскольку у нас есть зависимая переменная (x) с горячим кодированием (One-Hot Encoding), мы не можем напрямую использовать nll_loss или softmax(и, следовательно, не можем использовать cross_entropy):
- softmax, как мы видели, требует, чтобы сумма всех прогнозов равнялась 1, и имеет тенденцию подталкивать одну активацию к тому, чтобы она была намного больше, чем другие (за счет использования exp); однако у нас вполне может быть несколько категорий,к котором принадлежит изображение, поэтому ограничение максимальной суммы активаций до 1 - не лучшая идея. По тем же соображениям мы можем захотеть, чтобы сумма была меньше 1, если изображение не принадлежит ни к какой из категорий.
- nll_loss, как мы видели, возвращает значение только одной активации: единственной активации, соответствующей единственной метке для элемента. Это не имеет смысла, когда у нас несколько категорий.
С другой стороны, binary_cross_entropy функция, похожа наmnist_lossс log, предоставляет именно то, что нам нужно, благодаря магии поэлементных операций PyTorch. Каждая активация будет сравниваться с каждой целью для каждого столбца, поэтому нам не нужно ничего делать, чтобы эта функция работала для нескольких столбцов.
j: Одна из вещей, которые мне действительно нравятся в работе с такими библиотеками, как PyTorch, с широковещательными и поэлементными операциями, заключается в том, что довольно часто я нахожу, что могу написать код, который одинаково хорошо работает для одного элемента или пакета элементов, без изменений. binary_cross_entropy-отличный пример этого. Используя эти операции, мы не должны сами писать циклы и можем полагаться на PyTorch, чтобы сделать цикл, который нам нужен, в соответствии с рангом тензоров.
PyTorch уже предоставляет нам эту функцию. Фактически, он предоставляет несколько версий с довольно запутанными названиями!
F.binary_cross_entropy и его модульный эквивалент nn.BCELossвычисляют кросс-энтропию для метки с горячим кодированием(One-Hot Encoding), но не включают начальную sigmoid.Обычно для целей с горячим кодированием(One-Hot Encoding) требуется F.binary_cross_entropy_with_logits (или nn.BCEWithLogitsLoss), которые выполняют как сигмоидную, так и двоичную кросс-энтропию в одной функции, как в предыдущем примере. Эквивалент для наборов данных с одной меткой (таких как MNIST или набор данных Pet), где метка кодируется как единое целое, - это F.nll_loss либо nn.NLLLoss для версии без начального softmax и F.cross_entropy или nn.CrossEntropyLoss для версии с начальным softmax.
Поскольку у нас есть цель с горячим кодированием(One-Hot Encoding), мы будем использовать BCEWithLogitsLoss:
loss_func = nn.BCEWithLogitsLoss()
loss = loss_func(activs, y)
lossTensorMultiCategory(1.0342, grad_fn=<AliasBackward>)
На самом деле нам не нужно указывать fastai использовать эту функцию потерь (хотя мы можем, если мы захотим). fastai знает, что DataLoaders имеет несколько меток категорий и автоматически будет использовать nn.BCEWithLogitsLoss по умолчанию.
Одно изменение по сравнению с предыдущей главой - это метрика, которую мы используем: поскольку это проблема с несколькими метками, мы не можем использовать функцию точности. Это почему? Что ж, точность заключалась в сравнении наших результатов с нашими целями следующим образом:
def accuracy(inp, targ, axis=-1):
"Compute accuracy with `targ` when `pred` is bs * n_classes"
pred = inp.argmax(dim=axis)
return (pred == targ).float().mean()Прогнозируемый класс имел самую высокую активацию (это то, что делает argmax). Здесь это не работает, потому что у нас может быть более одного прогноза для одного изображения. После применения сигмоида к нашим активациям (чтобы сделать их между 0 и 1), нам нужно решить, какие из них равны 0, а какие - 1, выбрав порог. Каждое значение выше порога будет считаться 1, а каждое значение ниже порога будет считаться 0:
def accuracy_multi(inp, targ, thresh=0.5, sigmoid=True):
"Compute accuracy when `inp` and `targ` are the same size."
if sigmoid: inp = inp.sigmoid()
return ((inp>thresh)==targ.bool()).float().mean()Если мы передадим accuracy_multi метрику напрямую, она будет использовать значение по умолчанию, равное thresh равное 0,5. Возможно, мы захотим изменить это значение и создать новую версию accuracy_multi с другим значением по умолчанию. Чтобы помочь с этим, в Python есть функция partial. Это позволяет нам связать функцию с некоторыми аргументами или ключевыми словами аргументов, создавая новую версию этой функции, которая при каждом вызове всегда включает значения этих аргументов. Например, вот простая функция, принимающая два аргумента:
def say_hello(name, say_what="Hello"): return f"{say_what} {name}."
say_hello('Jeremy'),say_hello('Jeremy', 'Ahoy!')('Hello Jeremy.', 'Ahoy! Jeremy.')
Мы можем переключиться на французскую версию этой функции, используя partial:
f = partial(say_hello, say_what="Bonjour")
f("Jeremy"),f("Sylvain")('Bonjour Jeremy.', 'Bonjour Sylvain.')
Теперь мы можем обучить нашу модель. Попробуем установить порог точности 0,2 для нашей метрики:
learn = cnn_learner(dls, resnet50, metrics=partial(accuracy_multi, thresh=0.2))
learn.fine_tune(3, base_lr=3e-3, freeze_epochs=4)| epoch | train_loss | valid_loss | accuracy_multi | time |
|---|---|---|---|---|
| 0 | 0.941853 | 0.693213 | 0.237171 | 00:15 |
| 1 | 0.826186 | 0.557838 | 0.288705 | 00:14 |
| 2 | 0.604664 | 0.197422 | 0.828207 | 00:17 |
| 3 | 0.360535 | 0.122075 | 0.945080 | 00:17 |
| epoch | train_loss | valid_loss | accuracy_multi | time |
|---|---|---|---|---|
| 0 | 0.131160 | 0.117317 | 0.943068 | 00:17 |
| 1 | 0.116990 | 0.107440 | 0.953028 | 00:16 |
| 2 | 0.097601 | 0.102954 | 0.952311 | 00:16 |
Выбор порога важен. Если вы выберете слишком низкий порог (thresh), то часто не сможете выбрать правильно помеченные объекты. Мы можем увидеть это, изменив нашу метрику, а затем вызвав validate, который возвращает потери на проверочной выборке и метрики:
learn.metrics = partial(accuracy_multi, thresh=0.1)
learn.validate()(#2) [0.10295412689447403,0.9311155676841736]
Если вы выберете слишком высокий порог, вы будете выбирать только те объекты, для которых ваша модель очень уверена:
learn.metrics = partial(accuracy_multi, thresh=0.99)
learn.validate()(#2) [0.10295412689447403,0.9424302577972412]
Мы можем найти лучший порог(thresh), попробовав несколько уровней и увидев, что работает лучше всего. Это намного быстрее, чем если мы просто возьмем предсказания один раз:
preds,targs = learn.get_preds()Теперь мы можем использовать этот подход, чтобы найти лучший пороговый уровень:
xs = torch.linspace(0.05,0.95,29)
accs = [accuracy_multi(preds, targs, thresh=i, sigmoid=False) for i in xs]
plt.plot(xs,accs);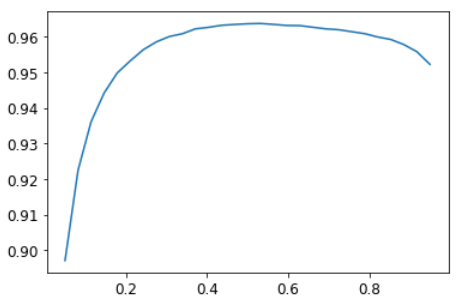
В этом случае мы используем проверочной набор, чтобы выбрать гиперпараметр (порог), что является нашей целью. Иногда студенты выражали озабоченность по поводу того, что мы, слишком скупулезно подходим к набору валидации, поскольку мы пробуем множество значений, чтобы увидеть, какое из них является лучшим. Однако, как вы видите на графике, изменение порога(thresh) в этом случае приводит к плавной кривой, поэтому мы явно не выбираем какой-то неподходящий выброс. Это хороший пример того, где вы должны быть осторожны с различиями между теорией (не пробуйте много значений гиперпараметров, иначе вы можете переоценить результаты на проверочном наборе) и практикой (если связь гладкая, тогда это нормально) .
На этом завершается часть этой главы, посвященная классификации с несколькими метками. Далее мы рассмотрим проблему регрессии.
Регрессия
Легко представить, что модели глубокого обучения классифицируются по областям применения, таким как компьютерное зрение, НЛП и так далее. И действительно, так fastai классифицирует свои приложения - во многом потому, что так привыкло думать большинство людей .
Но на самом деле, это скрывает более интересную и более глубокую перспективу. Модель определяется ее независимыми и зависимыми переменными, а также ее функцией потерь. Это означает, что существует гораздо более широкий спектр моделей, чем просто разбиение на основе предметной области. Возможно, у нас есть независимая переменная, которая является изображением, и зависимый текст (например, создание подписи из изображения); или, возможно, у нас есть независимая переменная, которая является текстом и зависимой, которая является изображением (например, генерация изображения из подписи - что на самом деле возможно для глубокого обучения!); или, возможно, у нас есть изображения, тексты и табличные данные как независимые переменные, и мы пытаемся предсказать покупки продуктов... возможности действительно бесконечны.
Необходимо выйти за рамки фиксированных задач, создать собственные новые решения проблем, это также поможет понять API блока данных (и, возможно, API среднего уровня, который мы позже увидим). В качестве примера рассмотрим проблему регрессии изображения. Это относится к обучению из набора данных, где независимая переменная является изображением, а зависимая переменная является одним или несколькими числами с плавающей запятой. Часто люди рассматривают регрессию изображения как отдельную задачу, но, как вы увидите, мы можем рассматривать ее как просто еще одну CNN (нейронную сеть) поверх API блока данных.
Мы собираемся перейти к несколько хитроумному варианту регрессии изображения, потому что мы знаем, что вы к этому готовы ! Мы собираемся создать модель ключевых точек. Ключевая точка представляет координаты по оси х и y на изображении. Мы будем использовать изображения людей и будем искать центр лица человека. Это означает, что мы фактически прогнозируем два значения для каждого изображения: строку и столбец - центр лица,ключевую точку.
Соберите данные
Для этого раздела мы будем использовать набор данных Biwi Kinect Head Pose . Начнем с загрузки набора данных как обычно:
path = untar_data(URLs.BIWI_HEAD_POSE)#hide
Path.BASE_PATH = pathПосмотрим, что у нас есть!
path.ls().sorted()(#50) [Path('01'),Path('01.obj'),Path('02'),Path('02.obj'),Path('03'),Path('03.obj'),Path('04'),Path('04.obj'),
Path('05'),Path('05.obj')...]
Есть 24 каталога, пронумерованных от 01 до 24 (они соответствуют разным фотографируемым людям), и соответствующий файл .obj для каждого (они нам здесь не понадобятся). Заглянем внутрь одного из этих каталогов:
(path/'01').ls().sorted()(#1000) [Path('01/depth.cal'),Path('01/frame_00003_pose.txt'),Path('01/frame_00003_rgb.jpg'),Path('01/frame_00004_pose.txt'),
Path('01/frame_00004_rgb.jpg'),Path('01/frame_00005_pose.txt'),Path('01/frame_00005_rgb.jpg'),
Path('01/frame_00006_pose.txt'),Path('01/frame_00006_rgb.jpg'),Path('01/frame_00007_pose.txt')...]
Внутри подкаталогов у нас есть разные кадры, каждый из которых содержит изображение ( _rgb.jpg ) и файл позы ( _pose.txt ). Мы можем легко получить все файлы изображений рекурсивно get_image_files, а затем написать функцию, которая преобразует имя файла изображения в связанный с ним файл позы:
img_files = get_image_files(path)
def img2pose(x): return Path(f'{str(x)[:-7]}pose.txt')
img2pose(img_files[0])Path('16/frame_00710_pose.txt')
Давайте посмотрим на наше первое изображение:
im = PILImage.create(img_files[0])
im.shape(480, 640)
im.to_thumb(260)
Веб-сайт набора данных Biwi используется для объяснения формата текстового файла позы, связанного с каждым изображением, который показывает расположение центра головы. Для наших целей, детали не важны , поэтому мы просто покажем функцию, которую мы используем для извлечения центральной точки головы:
cal = np.genfromtxt(path/'01'/'rgb.cal', skip_footer=6)
def get_ctr(f):
ctr = np.genfromtxt(img2pose(f), skip_header=3)
c1 = ctr[0] * cal[0][0]/ctr[2] + cal[0][2]
c2 = ctr[1] * cal[1][1]/ctr[2] + cal[1][2]
return tensor([c1,c2])Эта функция возвращает координаты в виде тензора двух элементов:
get_ctr(img_files[0])tensor([316.7118, 287.0693])
Эту функцию можно передать DataBlock как get_y, поскольку она отвечает за маркировку каждого предмета. Мы изменим размер изображений до половины, чтобы немного ускорить обучение.
Следует отметить один важный момент: мы не должны просто использовать случайный разделитель. Причина этого в том, что одни и те же люди появляются на нескольких изображениях в этом наборе данных, но мы хотим убедиться, что наша модель может обобщить людей, которых она еще не видела. Каждая папка в наборе данных содержит изображения для одного человека. Следовательно, мы можем создать функцию-разделитель, которая возвращает истину только для одного человека,в результате чего получается проверочный набор только для этого человека.
Единственное отличие от предыдущих примеров блока данных - то, что второй блок - PointBlock. Это необходимо для того, чтобы fastai знал, что метки представляют координаты и при изменение изображения должно выполняться такое же изменение координат:
biwi = DataBlock(
blocks=(ImageBlock, PointBlock),
get_items=get_image_files,
get_y=get_ctr,
splitter=FuncSplitter(lambda o: o.parent.name=='13'),
batch_tfms=[*aug_transforms(size=(240,320)),
Normalize.from_stats(*imagenet_stats)]
)Важно: координаты и увеличение данных: нам не известны другие библиотеки (кроме fastai), которые автоматически и правильно применяют увеличение данных к координатам. Итак, если вы работаете с другой библиотекой, вам может потребоваться отключить увеличение данных для такого рода проблем.
Перед тем как приступить к моделированию, мы должны взглянуть на наши данные, чтобы убедиться, что все в порядке:
dls = biwi.dataloaders(path)
dls.show_batch(max_n=9, figsize=(12,10))
Выглядит хорошо! Помимо визуального просмотра пакета, неплохо также посмотреть на лежащие в основе тензоры (особенно в качестве студента; это поможет прояснить ваше понимание того, что на самом деле видит ваша модель):
xb,yb = dls.one_batch()
xb.shape,yb.shape(torch.Size([64, 3, 240, 320]), torch.Size([64, 1, 2]))
Убедитесь, что вы понимаете, почему именно эти формы используются в наших мини-партиях.
Вот пример одной строки из зависимой переменной:
yb[0]TensorPoint([[-0.2603, 0.0405]], device='cuda:0')
Как видите, нам не пришлось использовать отдельное приложение для регрессии изображений ; все, что нам нужно было сделать, это пометить данные и сообщить fastai, какие типы данных представляют независимые и зависимые переменные.
То же самое и с нашим Learner. Мы будем использовать ту же функцию, что и раньше, с одним новым параметром.
Обучение модели
Как обычно, мы можем использовать cnn_learner для создания нашего Learner. Помните, как раньше в < > мы использовали y_range, чтобы определить диапазон наших целей? Мы сделаем то же самое здесь (координаты в fastai и PyTorch всегда масштабируются между -1 и + 1):
learn = cnn_learner(dls, resnet18, y_range=(-1,1))y_range реализуется в fastai с использованием sigmoid_range, который определяется как:
def sigmoid_range(x, lo, hi): return torch.sigmoid(x) * (hi-lo) + loОн устанавливается как последний слой модели, если определен y_range. Подумайте о том, что делает эта функция и почему она заставляет модель выводить активации в диапазоне (lo,hi).
Вот как это выглядит:
plot_function(partial(sigmoid_range,lo=-1,hi=1), min=-4, max=4)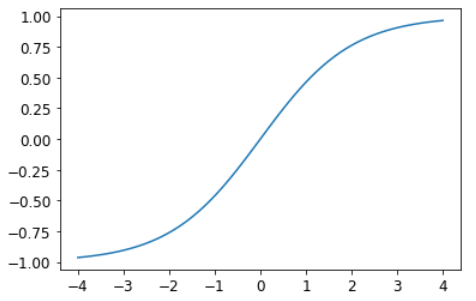
Мы не указали функцию потерь, что означает, что мы получим все, что выберет fastai по умолчанию. Посмотрим, что он нам подобрал:
dls.loss_funcFlattenedLoss of MSELoss()
Это имеет смысл, поскольку, когда координаты используются в качестве зависимой переменной, большую часть времени мы, вероятно, пытаемся предсказать что-то как можно более близкое; это в основном то, что делает MSELoss (mean squared error loss). Если вы хотите использовать другую функцию потерь, вы можете передать ее cnn_learner с помощью параметра loss_func.
Обратите внимание также, что мы не указали никаких метрик. Это потому, что MSE уже является полезной метрикой для этой задачи (хотя она, вероятно, более интерпретируема после того, как мы возьмем квадратный корень).
Мы можем выбрать хорошую скорость обучения с помощью средства поиска скорости обучения:
learn.lr_find()SuggestedLRs(lr_min=0.00831763744354248, lr_steep=1.0964781722577754e-06)
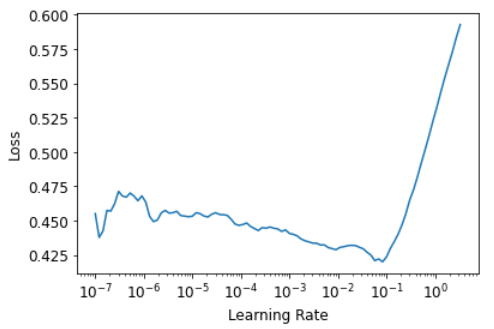
Мы попробуем LR 1e-2:
lr = 1e-2
learn.fine_tune(3, lr)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 0.051521 | 0.057012 | 01:08 |
| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 0.008148 | 0.001204 | 01:27 |
| 1 | 0.003119 | 0.001155 | 01:29 |
| 2 | 0.001552 | 0.000116 | 01:32 |
Как правило, когда мы выполняем это, мы получаем потерю около 0,0001, что соответствует средней ошибке предсказания координат:
math.sqrt(0.0001)0.01
Звучит очень точно! Но важно взглянуть на наши результаты Learner.show_results. Левая часть - это фактические ( точные ) координаты, а правая часть - это прогнозы нашей модели:
learn.show_results(ds_idx=1, nrows=2, figsize=(12,10))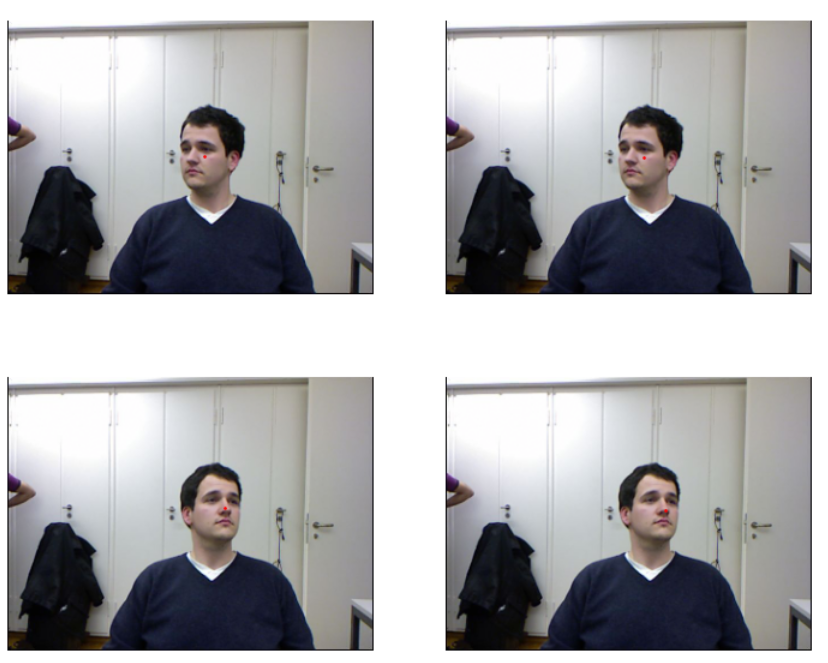
Просто удивительно, что всего за несколько минут вычислений мы создали такую точную модель ключевых точек и без какого-либо специального приложения для конкретной области. Это сила построения гибких API и использования трансфертного обучения! Особенно поразительно, что мы смогли так эффективно использовать трансферное обучение даже между совершенно разными задачами; наша предварительно обученная модель была обучена классификации изображений, и мы точно настроили регрессию изображений.
Вывод
В задачах, которые на первый взгляд совершенно разные (классификация по одной метке, классификация по нескольким меткам и регрессия), мы в конечном итоге используем одну и ту же модель с разным количеством выходов. Функция потерь - это единственное, что меняется, поэтому важно дважды проверить, что вы используете правильную функцию потерь для своей задачи.
fastai автоматически попытается выбрать правильный вариант из построенных вами данных, но если вы используете чистый PyTorch для создания своих DataLoaders, убедитесь, что вы хорошо подумали, когда вам нужно будет принять решение о выборе функции потерь, и помните, что вы, скорее всего, захотите:
- nn.CrossEntropyLoss для однокомпонентной классификации
- nn.BCEWithLogitsLoss для классификации по нескольким меткам
- nn.MSELoss для регрессии
Опросник
- Как классификация с несколькими метками может повысить удобство использования классификатора медведей?
- Как мы закодируем зависимую переменную в задаче классификации с несколькими метками?
- Как получить доступ к строкам и столбцам DataFrame, как если бы это была матрица?
- Как получить столбец по имени из DataFrame?
- В чем разница между a Datasetи DataLoader?
- Что Datasetsобычно содержит объект?
- Что DataLoadersобычно содержит объект?
- Что делает lambdaв Python?
- Какие есть методы для настройки создания независимых и зависимых переменных с помощью API блока данных?
- Почему softmax не является подходящей функцией активации выхода при использовании одной цели с горячим кодированием?
- Почему nll_lossне подходит функция потерь при использовании цели с одним горячим кодированием?
- В чем разница между nn.BCELossи nn.BCEWithLogitsLoss?
- Почему мы не можем использовать обычную точность в задаче с несколькими метками?
- Когда можно настраивать гиперпараметр в наборе для проверки?
- Как y_rangeреализовано в фастай? (Посмотрите, сможете ли вы реализовать это самостоятельно и протестировать, не заглядывая!)
- Что такое проблема регрессии? Какую функцию потерь следует использовать для такой задачи?
- Что вам нужно сделать, чтобы убедиться, что библиотека fastai применяет такое же увеличение данных к вашим входным изображениям и координатам вашей целевой точки?
Дальнейшие исследования
- Прочтите руководство по Pandas DataFrames и поэкспериментируйте с несколькими методами, которые вам интересны. См. Рекомендуемые уроки на веб-сайте книги.
- Переобучите классификатор медведей, используя классификацию с несколькими метками. Посмотрите, сможете ли вы заставить его эффективно работать с изображениями, не содержащими медведей, включая отображение этой информации в веб-приложении. Попробуйте изображение с двумя разными видами медведей. Проверьте, не влияет ли на точность набора данных с одной меткой, используя классификацию с несколькими метками.
Метки


Раскрыть комментарии 0
Чтобы оставить комментарий , Вам необходимо Авторизоваться или пройти Регистрацию